论文笔记 Learning non-maximum suppression
Abstract
目标检测器受益于端到端的训练范式:推荐、特征、分类器开始成为一个神经网络。另一个独立不可缺的组件是NMS,一个后处理算法将属于同一目标的bbox合并。NMS仍然是手工设计,策略简单,基于固定阈值的贪心聚类算法,导致召回率和精度之间权衡。我们提出一个新的网络架构来实现NMS,仅基于其box和得分。我们在PETS上验证行人检测和COCO上验证目标检测。结果表明该方法能够改进定位和遮挡问题。
1. Introduction
2. Related Work
聚类检测 贪心NMS作为标准算法从VJ一直应用于目前SOTA的算法。也有一些其他的聚类算法用于NMS,但是没有显示明显的提升:mean-shift 聚类[^6],[^35], agglomerative 聚类[^2], affinity 聚类[^17], 启发式变体[^25]。 在[^27],[^23]中提出全局优化的原则聚类函数,尽管其还未用于贪心NMS。
面向像素检测 Hough投票建立了检测结果和图像证据直接的关系,这能够避免过度使用图像内容。但是整体上说hough投票的效果较差。论文[^37],[^5]结合语义标签,论文[^36]将检测作为labelling问题。这些方法依赖更多的信息,但是我们的系统纯粹基于检测结果。
同现 有些工作提出检测目标群,而不是检测独立的个体来解决较强的遮挡问题,这个问题比NMS更复杂。论文[^22] 基于密度估计来抑制检测结果。我们的方法既不用图片信息也不用手工标记的成对目标。
自语义 一些方法使用局部[^30],[^4]或全局[^31]图像信息重打分。这些方法会产生一些分离的双检测结果并且改进全局的检测治理,但是仍然需要NMS。我们将NMS作为一个重打分的问题,并且取消了后处理。
图神经网络 一组检测结果可以被认为是一个图,具有重叠的窗口可以被认为是图中的边。论文[^18]在图上操作,但是其要求前处理过程定义节点顺序,在我们的问题中是模糊的。
端到端的学习 很少有工作将NMS纳入端到端学习中。一种想法是在训练时包含NMS[^32],[^12],使其能够得到实际测试时的结果,这样做更合理,但是并没有使NMS可学习。另一个想法是直接生成稀疏的结果使得NMS没有必要,论文[^26]在图像重叠patch上生成检测结果,但是在patch边缘仍然需要NMS。论文[^13]设计一个卷积网络结合NMS和不同的iou阈值进行决策,其网络选择需要NMS的局部区域。但是上述方法都没有完全消除NMS直接生成稀疏的结果。我们的网络有能力直接进行抑制操作,而不是选择一些子集再经过最后的抑制步骤。
3. 检测和非极大值抑制
本节我们回归非极大值抑制为何必须,并且我们指出为何当前的检测器不能对一个目标输出一个结果,提出两个检测器必要的部件。
目前检测器不返回所有检测结果,而是使用NMS作为后处理步骤去除冗余的结果。为了实现端到端学习的检测器,我们对没有后处理方法的检测器感兴趣。为了理解为何需要NMS,很有必要审视检测任务及其如何评估的。
目标检测 目标检测任务即在一张图上映射一组boxs:每个box对应一个目标并与其边缘贴紧。这意味着检测器应该对每个目标返回一个结果。由于检测过程的内在不确定性,评估时以检测结果的置信得分进行评估。得分高的错误检测比低得分的错误检测惩罚高,使得错误结果的得分低。
检测器不生成我们期望的结果 检测任务可以简化为分类任务,在图像中所有可能的地方进行分类。这个观点使得“假设和得分”检测器兴起,其构建一个搜索空间(滑窗,推荐)然后独立的估计每个检测是结果的类别概率。结果就是当两个重叠很大box对应相同的目标其得分均非常高,因为看起来几乎一样。一般来说,一个目标周围会生成多个高得分结果,得分跟目标的重叠率相关。
贪心NMS 为了实现一个目标一个结果,假设高重叠的检测属于一个目标,即选择置信分最高的结果,然后抑制与其IoU率超过阈值的结果。
贪心NMS不够好 该算法表现好有两个前提,1)能够抑制同一目标导致的多个检测结果;2)不会抑制接近的其他检测结果。如果目标分散条件2很容易达到,并且条件1也能工作很好。在拥挤场景,目标间具有很强的遮挡,宽抑制和窄抑制存在对抗。换句话说,一张图一个目标NMS是不重要的,但是对高遮挡问题,需要更换的NMS算法。
3.1 不需要NMS的未来
在没有手工算法的情况下实现真正端到端系统,我们不禁要问:为什么需要手工设计的后处理步骤?为什么检测器不能对一个目标输出一个结果?
重叠高的窗口具有较高的得分是鲁棒性的要求:相似的输入得到相似的输出。因此,检测器对一个目标输出一个检测结果那么需要结合其他检测结果。冗余的结果需要合并,从而使得检测器能分辨这些是重复的结果,只输出一个高得分。一般用IoU的阈值来定义正负样本,因此位置微小偏移时检测结果仍然认为是正样本。这样的训练数据增强方法是为了增加检测器的鲁棒性。但是这样的策略不会倾向于一个目标产生一个检测结果,而且产生多个高得分的结果。
因此,我们发现两个关键组件:
- 一种损失函数能够惩罚冗余检测结果
- 联合处理周围的结果,使得检测器获得足够的信息来判断该目标是否被检测多次
本文,我们设计一个网络结合上述两个组件。为了验证我们的网络能够实现NMS,仅对检测结果和得分进行操作,而不采用图像特征。
4. 使用网络进行NMS
我们的方法避免硬决定,并且不会抛弃一些检测结果。除此之外,我们将NMS作为重打分任务。在重打分之后,简单的阈值选择就能够减少检测结果。我们将所有重打分的结果进行评估,不进行任何后处理过程。
4.1 损失
在计算损失的时候加入benchmark的评估中采用匹配方法。匹配上的作为正样本,否则作为负样本。
$$
L(s_i,y_i)=\sum^N_{i=1}w_{y_i}\cdot log(1+exp(-s_i\cdot y_i))
$$
$s_i$是检测得分,$y_i$是预测类别。权重$w_{y_i}$用于平衡检测任务的样本不平衡。面对多类别问题时,检测结果有得分和类别,在处理时我们仍然将每个类别当作二元分类问题。
表征检测得分我们使用热编码:一个零向量在该类别对应的位置包含其得分。由于mAP计算是为考虑样本的数量,因此我们实际的权重也是将其当做均匀分布的。
4.2 “Chatty”windows ”交流窗口

为了最小化上述loss,我们需要网络处理结果联系。为此,我们设计了一个循环结构称为block(如图3)。一个block给每个检测结果与其周围结果的表示,并更新自己的表示。堆叠多个block后意味着网络能够允许检测结果之间交流,并更新自己的特征表示。我们成其为GossipNet(Gnet)。
这里有两个非标准的操作是关键。1. 构建成对检测结果的特征表示层;这导致一个关键问题:每个结果周围的结果输了是不一定的;2.因此我们后续使用池化来解决。
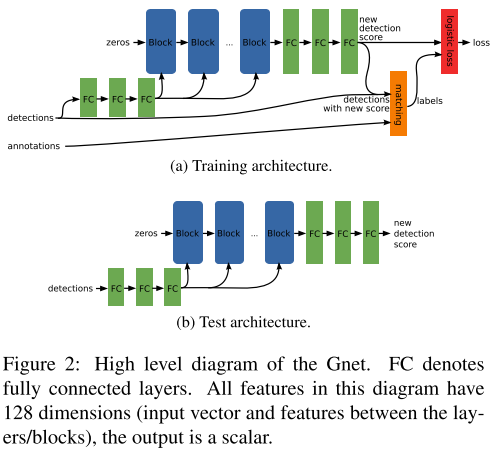
检测特征 block的输入是检测结果的特征向量,输出是更新向量,如图2所示。特征纬度是128维。最后输出每个检测结果的更新得分。第一个block以全零向量作为输入,检测结果信息输入网络的pairwise计算步骤。
Pairwise 检测语义 每个mini-batch包含n个检测结果,每个结果用c维向量描述,因此数据量为$n\times c$ 。对每个检测结果 $d_i$ ,生成与其相交$(IoU>0.2)$的成对结果$(d_i,d_j)$。 特征两个d的特征和g维的成对特征则特征纬度为:$l=2c+g$ 。如果一个d周围一k个结果,那么生成的batc尺寸为$K\times l$。k的数量可能不一样,因此采用全局最大池化合并为一个结果,然后使用全连接层更新结果。
检测对特征 监测对的语义特征包含几个属性:1) IoU;2)-3) 归一化的x,y距离;4)-5) 宽高变化;6) 宽高比变化; 7)-8) 两个检测得分。如果是多类问题,得分是一个向量而不是标量。我们将这些特征输入3个全连接层,用于学习g检测对特征。
Block block的作用是让检测结果基于他们的邻居更新表示。其包含降维,成对检测语义层,2个全连接成,池化层,全连接层最后一层用于增加维度。最后提供三个fc层用于预测新得分。
参数 网络包含16个block,检测特征128维,在检测对时缩减为32维,最后输出又扩增为128维。若我们改变特征维度,我们帮助每层的特征比例一致。
信息传递 前向过程通过block可以解释为信息传递。每个检测结果传递信息给邻近结果,并降低得分,为了替代手工设计信息传递算法,我们使得网络潜在自动学习。
4.3 Remarks
Gnet没有使用NMS但是效果与采用了NMS的Tnet接近。Gnet网络更大,因此采用训练样本更多的妨害。
Gnet是个纯NMS功能网络,不需要图像特征,仅在检测结果上进行操作。意味着Gnet不能当做网络层加入检测器。而事实上是可以这么整合的,我们在未来会开展研究。
我们的目标是联合图像上所有检测结果进行重打分。通过允许检测结果观察旁边的结果来更新自身的表示。实验表面模型对参数的鲁棒性,并且随着深度的增加性能变优。
5. 实验
数据集PETS和COCO。评估指标average precision,AP。
5.1 PET数据集
该数据集一般用于单一尺度行人检测,包含不同的遮挡程度。首先按照论文[^13]和论文[^28]的设置进行训练和测试。
训练模型包含8个block,128维输入特征,30k迭代,学习率0.001,每10k次衰减0.1。
NMS和Tnet作为baseline
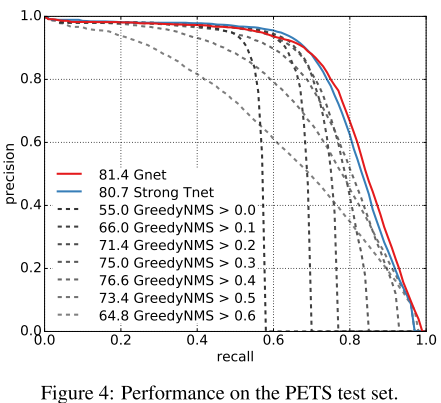
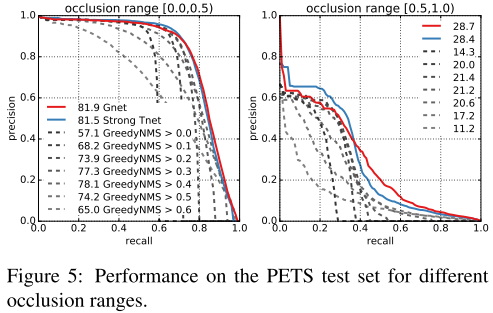
图4显示了结果,NMS阈值高被抑制的结果多,Gnet相比于最后的NMS提升了4.8个AP。图5显示了对不同遮挡级别的结果,Gnet比Tnet稍好。在遮挡高的情况下Gnet比NMS提升7.3AP。
5.2 COCO:行人检测
Faster R-CNN作为基准,Gnet使用ADAM训练2*1000K次迭代,学习率0.0001,每1000K次减少到0.00001。速度14ms/image,评价67.3检测结果。
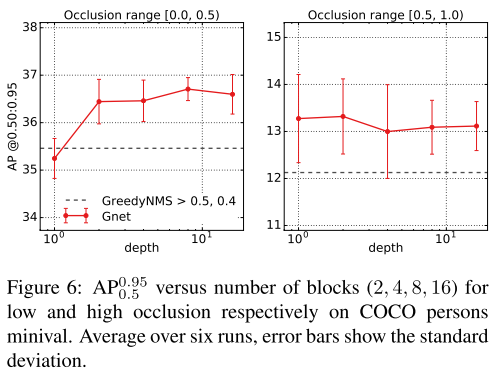
图6显示了block数量和性能的关系,随着网络月神,性能鲁棒性越好。我们能够Gnet能够替代NMS,
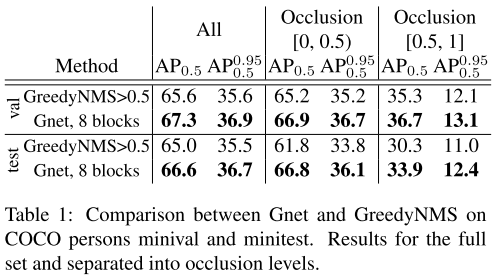
表1显示了Gnet和NMS的量化对比。

图7显示了Gnet对多类别检测时的作用,大部分类别有提示,少部分降低。
6. 结论
本文提出Gnet用于替代NMS,其主要包含两个关键组件:1)惩罚同一目标生成两个结果;2)联合处理所有结果。该网络能够实现端到端训练。结果显示相比于NMS,Gnet的后处理效果更好。目前Gnet需要大量训练数据,未来会研究通过数据增强或更好的预训练初始化模型。以及配合图像特征进行处理。我们相信本文提出的想法和结果能够使得未来检测器和NMS的分离消失。