论文笔记《A unified multi-scale deep convolutional neural network for fast object detection》

Abstract
本文主要提出了一个多分支的检测网络来匹配多尺度目标的感知域和anchor尺寸。
- multi-scale CNN for fast multi-scale object detection
- proposal sub-network detect at multi output layer
- scale-specific detectors combined
- optimizing a multi-task loss
- feature upsampling by deconvolution
1. Introduction
Motivation
- 目标检测主要基于滑窗法来搜索多尺度多比例的目标。
- 这些方法虽然在人脸、行人检测能够实现实时的检测,但是在多类目标检测却很困难
- R-CNN 利用预选的ROI,将其缩放到224 $\times$ 224 用CNN进行分类,这样在计算效率底下
- Faster R-CNN 固定了 receptive field 感知域(这里主要指RPN)
Invention
- MS-CNN
- 为了目标尺寸和感知域不一致的问题,proposal 网络在多层进行预测,每层针对特定尺寸的目标
- 各个层的检测器组合成一个strong multi-scale detector
- 对特征图升采样替代对图像升采样,能够减少计算量和内存
2. Related Work
最早实现实时检测是级联 (cascaded) 检测器VJ[^1] ,之后有两条研究路径提高效率:
快速特征提取:VJ使用积分图计算Haar特征,之后ACF在其基础上实现100fps的HOG特征计算。
级联学习:软级联[^14],拉格朗日公式学习级联[^17],学习异质 (heterogeneous) 特征[^15]
级联检测器的问题是,在此框架下很难实现多类检测
此后,相关研究尝试使用深度神经网络提升目标分类
- R-CNN,组合了目标推荐机制和CNN分类器,但是速度受到proposal数量和重复CNN计算的限制
- SPPnet,通过空间金字塔池化,实现一张图片只计算一次特征图,速度提升了一个数量级
- Fast R-CNN,提出了通过ROI池化和多任务学习(分类+回归)进行反向传播的思想,但是仍然依赖一个独立的proposal
- Faster R-CNN,使用相同的神经网络,从而极大的加快proposal的速度。
- YOLO,是另一个有趣的尝试,其能够实现~40 fps,但是会妥协一些精度
对于目标检测,一些研究表明在单一网络中组合中间层是有益的。
- GoogLeNet[^22], 提出在中间的高层网络上使用三加权分类损失,这样正则化方法对深层模型有效
- Full CNN[^11], 高层具有更高的语义信息,高层与中间层组合后实现更精确的语义分割。
MS-CNN与上面的方法类似,也从中间层计算损失,但是其目的不是正则化学习,而是为了提供更多的细节信息。并且是对每个中间层生成一个独立的目标检测器。
3. 多尺度目标推荐网络 Multi-scale Object Proposal Network
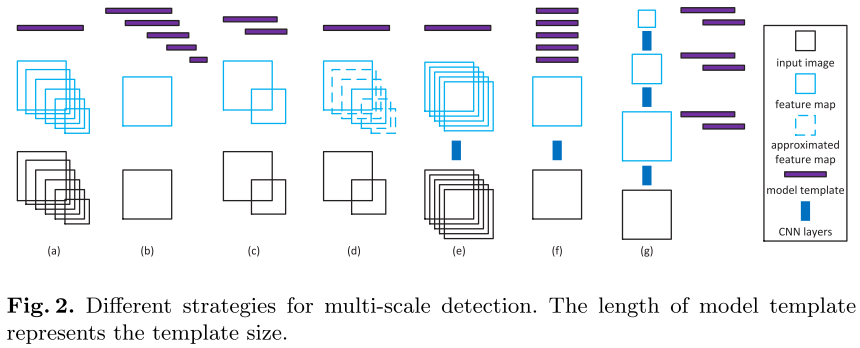
3.1 多尺度检测
覆盖各种尺寸的目标是目标检测的重要问题。
- 单一模型,多尺度图像和特征图,一般具有较好的精度,但是计算开销大
- 多个模型,单一图像尺寸和特征图,避免重复计算特征,但是对每个尺度生成一个检测器
- 多个模型,多个尺度图像和特征图,这样是上述两个方法的折中
- 单一模型,几个尺度图像和多个尺度特征图(估计),通过差值计算得到中间缺失的特征图
基于CNN的多尺度策略与上面的一些区别
- 将输入的目标区域全部缩放到同一尺寸计算卷积特征,R-CNN,类似a
- RPN,是在同一个特征图上将多尺寸的ROI生成相同尺寸的模型(一个检测器),类似b
- 收到c的启发,我们提出一个新的多尺度策略,从单一输入图像中,在多个中间特征层上进行多尺度的目标检测(后面SSD,FPN的做法也很类似)
3.2 网络结构
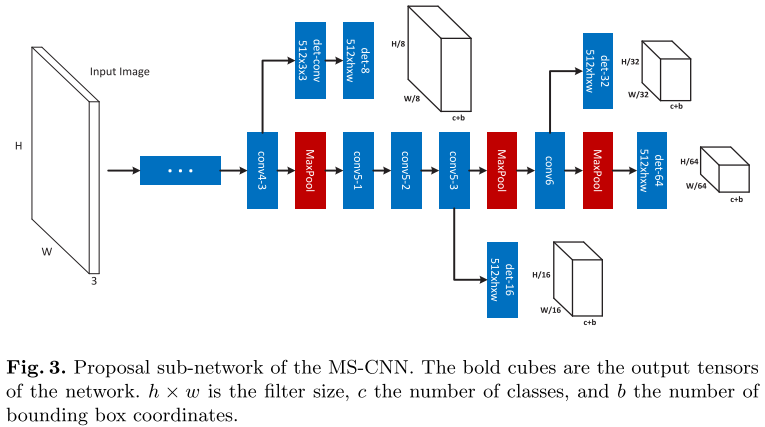
该网络有多个检测分支,每个检测分支都是最终的proposal检测结果。该网络有个标准的主干CNN,一组单一检测分支。
注意,这里在conv4-3之后开始建立检测分支,因为在之前,回传的梯度会对后面的检测结果具有较大影响,造成训练的不稳定。
多分支的联合损失

- $W$是网络参数
- $Y_i=(y_i,b_i)$是Ground Truth
- $X_i$是训练图像块
- $a_m$是损失权重
- $S={(X_i,Y_i)}_{i=1}^N={S^1,S^2,\dots,S^M}$ 是训练样本
- $M$ 是检测分支的数量
注意,属于$S^m$的样本只对其分支贡献损失,这个样本在训练之前会规划好。
损失$l^m$采用的是Faster R-CNN之前采用的方法,联合分类和回归损失
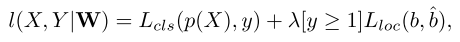
- 一个是多类分类损失
- 一个是定位损失,背景样本不提供定位损失
3.3 采样
对于每个检测层,$S^m={S^m _ +,S^m _ -}$
anchor尺寸是与filter的尺寸相关的,anchor与标记IoU$\ge$0.5认为是正样本,$\le$0.2认为是负样本。$|S_-|=\gamma|S_+|$
对于自然图像,目标和非目标的数量具有极大的不平衡。采样是为了补偿这种不平衡。考虑三种采样策略:随机,bootstrapping,混合。
- 随机采样获得的样本大量为随机样本,我们知道困难样本挖掘能提升性能
- Bootstrapping策略,用物体性得分对样本排序。然后从高到低收集负样本
- 混合策略,就是随和和bootstrapping一半一半,在我们的实验中其效果和bootstrapping相似
为了保证每个检测层只检测特定尺度范围的目标,训练集按照相应的范围组织。但是,在一张图中,一些尺度可能没有正样本,导致正负样本不平衡$|S_-|/|S_+|\gg\gamma$ ,导致学习不稳定。为了解决这个问题,交叉熵损失修改为:
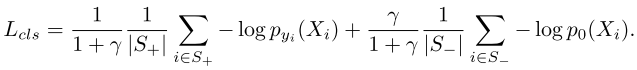
3.4 实现细节
数据增强 在[^4][^6] 中说,多尺度的训练不必要,因为深度神经网络适应尺度不变性。然而,在Caltech和KITTI这类数据集上不成立,因为目标的尺度范围可以跨多个倍数(octaves)。但是,不同尺寸的正样本数量也具有很大的差别。为了解决这个不平衡,对原图像进行随机缩放为多个尺度。
Fine-tuning Fast R-CNN 和 RPN原始训练一个小的mini-batch需要大量的内存,但是一个图像中有很多区域是没有用的背景。为了节省内存,我们在目标周围裁剪一个448 $\times$ 448 的图像块。这样能够极大的减少内存的需求,从而使得mini-batch能够适应4张图片,对一个12G内存的GPU。
网络采用流行的VGG16初始化。由于采用了bootstrapping和多任务损失,可能导致在早期的迭代中不稳定。因此采用two-stage步骤。
- 第一阶段,随机采样,定位损失系数小($\lambda=$0.05),迭代10000次,学习率0.00005。
- 第二阶段,bootstrapping采样,定位损失系数($\lambda=$1),“det-8”的检测分支损失$a_i=0.9$,其他检测分支系数为1,迭代25000次,学习率0.00005,每10000次缩小10倍。
two-stage训练流程能够实现稳定的多任务训练。
4. 目标检测网络
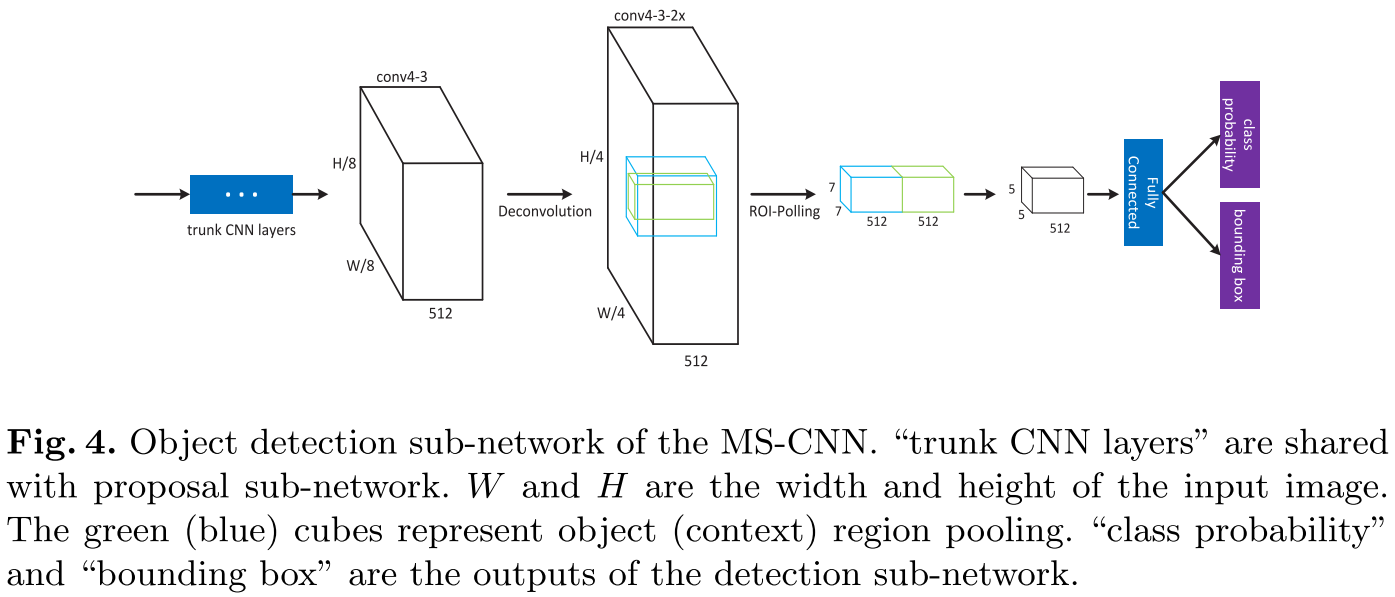
RPN本身虽然也可以作为检测器,但滑窗不能很好覆盖目标,所以不是很好。为了提高精度,因此增加了检测网络。ROI pooling层在特征图上提取固定维度的特征(7$\times$7$\times$512),然后送入fc层,如图4所示。这里增加了一个反卷机层来提升特征图分辨率。因此,多任务损失扩展为:

其中$l^{M+1}$和$S^{M+1}$损失和训练样本对于检测子网络。$S^{M+1}$是用Fast R-CNN方式采集。检测子网络与proposal子网络共享参数W,然后增加了一些参数$W_d$。ROI pooling应用于”conv4-3”具有更好的效果。可能的原因是”conv4-3”相对更高的分辨率,更适合位置感知的bounding box回归。
4.1 CNN 特征图估计
升采样虽然能提升小目标检测效果,但是有三个副作用:
- 内存需求增加
- 训练、测试慢
- 不会增加图像信息
我们考虑用更有效的方法提升特征图分辨率:
- 这个做法类似上面的图2(d)不是通过对图像缩放,而是对特征图缩放,采用最小二乘法估计
- 在CNN中,使用反卷积更好
- 特征图缩放,不会带来太多的计算和内存成本
据我们所知,这是第一次应用翻卷机到目标检测中,用于改善速度和精度
4.2 嵌入语义
在文献[^7][^5][^26]中表明语义信息对目标检测有用。本文专注于从多个区域中提取语义。如图4所示,我们从目标区域(绿色)和语义区域(蓝色)提取特征,然后堆叠在一起。语义区域是目标区域的1.5倍,后面增加一个卷积层减少通道数,从而保证在不增加模型参数的同时不损失精度。
4.3 实现细节
用3.4节描述的proposal网络训练好的结果初始化。学习率为0.0005,每10000次迭代减小10倍,25000次迭代后终止。通过反向传播优化(6)。使用Bootstrapping采样策略,$\lambda=1$,前两层”conv1-1”和”conv2-2”的参数固定,用于加速训练。
5. 实验评估
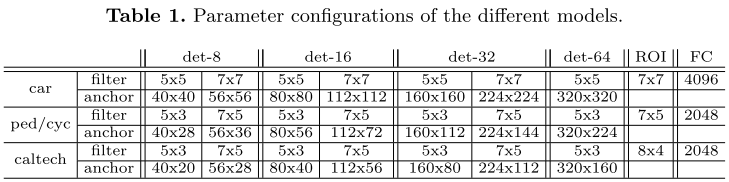
我们在KITTI和Caltech上评估MS-CNN检测器,不同于VOC和ImageNet,这两个数据集中有更多的小目标。由于KITTI没有测试集标注,我们参考[^5]的方法,将训练集分为训练和验证集,并且训练一个用于车辆检测,另一个用于行人/骑车人检测。表1描述了模型的对多尺度目标所使用的不同anchor。硬件平台E5-2630单核,64GB内存,TITAN GPU。
5.1 Proposal 评估
使用oracle recall用于评估指标[^31]。car的IOU大于等于70%,行人、骑车人IOU大于等于50%。
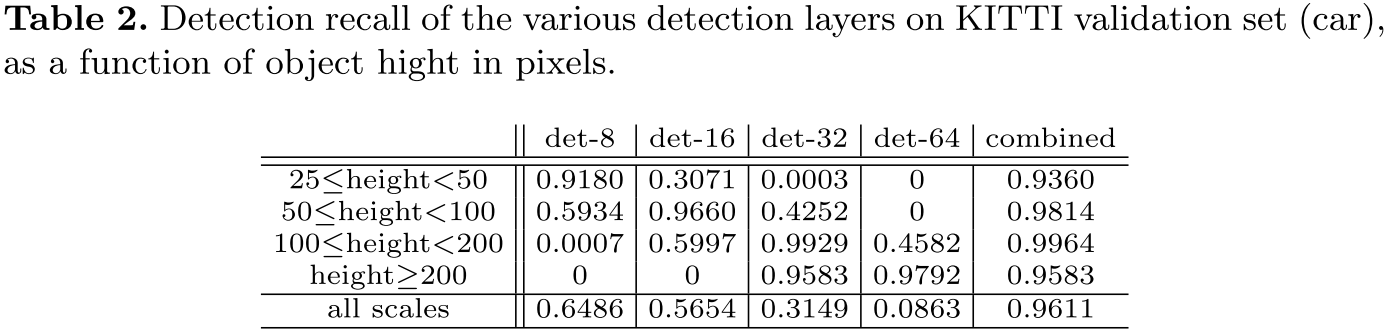
独立检测分支的作用 表2显示了不同检测分支与行人高度的检测精度关系。与期望的一致,尺度匹配的精度越高。
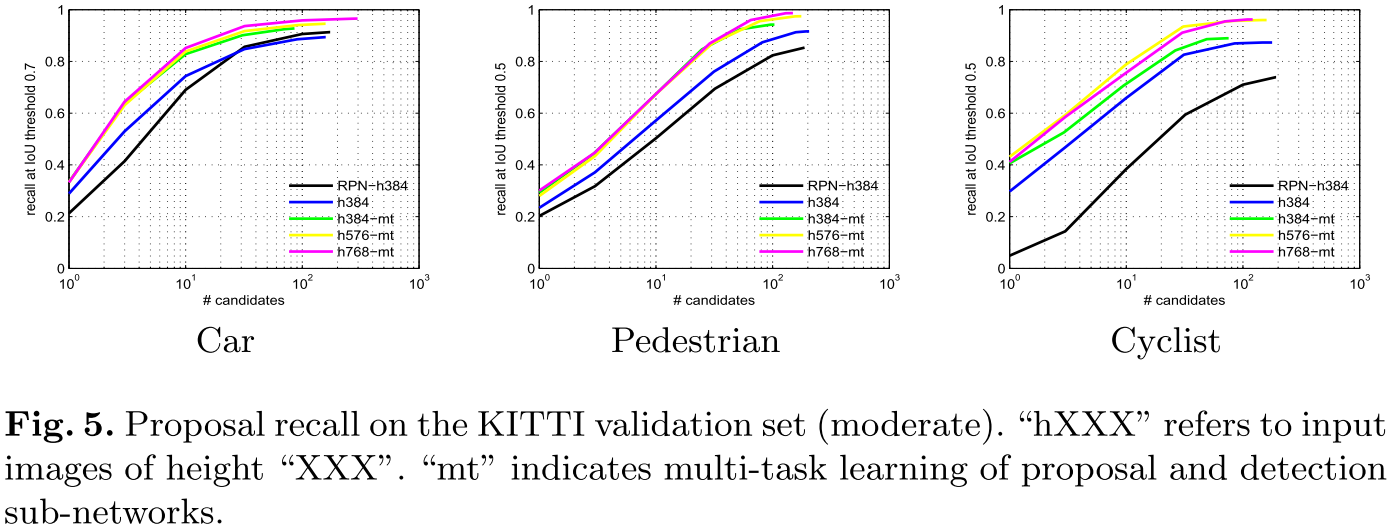
输入图像尺寸的作用 图5显示了proposal网络与输入图像尺寸的关系。行人和车辆的proposal网络对图像尺寸较为鲁棒,骑车行人从384-576性能有提升。这说明,proposal网络不需要增加图像输入尺寸也能得到较好的proposal结果。
检测子网络改进推荐子网络 论文[^4]表明多任务学习能有利于bb回归和分类。另一方面,论文[^9]显示,两个任务共享特征也并不能改进proposal。图5显示,多任务学习能有效帮助proposal的生成,尤其是对于行人。(这个跟我所实验的不一样,检测和推荐共享网络会相互干扰,原因可能是用)
与其他先进方法比较 图6比较了多种方法:BING[^32], Selective Search[^8], EdgeBoxes[^33], MCG[^34], 3DOP[^5], RPN[^9]。

图像第一排是IoU确定时,召回率与候选样本数量的关系。第二排是100个候选样本,召回率与IoU的关系。MS-CNN在只有100个proposal的情况下实现了98%的召回率。有监督学习的方法比无监督的方法好。RPN与MS-CNN的结果最接近,RPN对图像进行了两倍的上采样。MS-CNN能够与GT有高度的重合,说明了回归网络的作用。
5.2 目标检测评估
由于cyclist数量较少,本实验只考虑car 和 pedestrian。
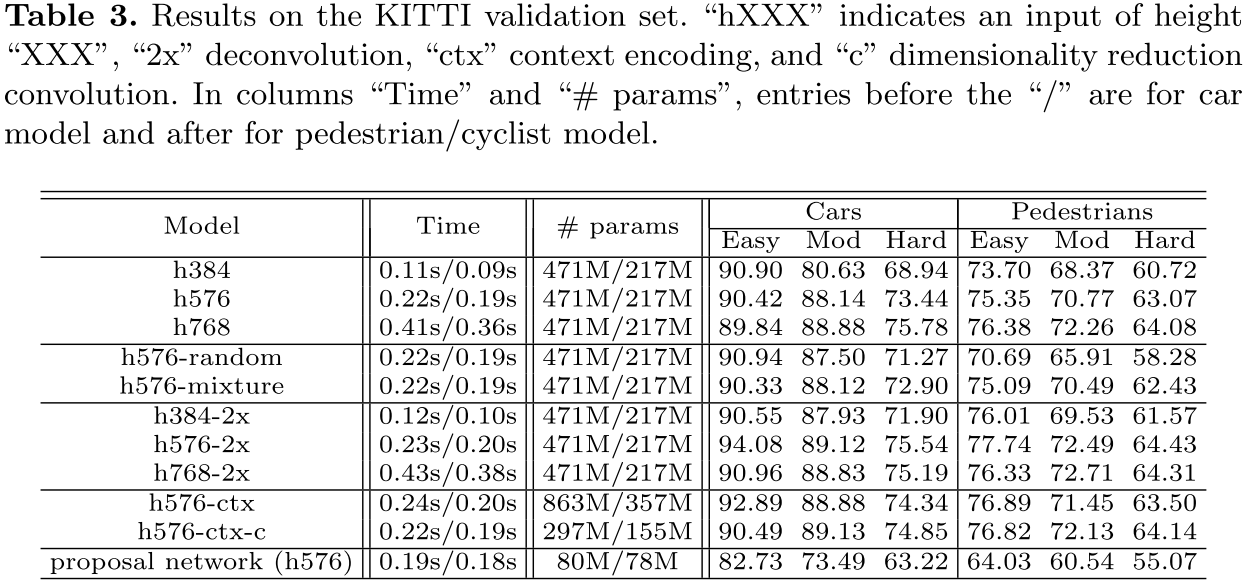
输入图像上采样的影响 表3显示了输入上采样是检测的很重要的因素。上采样1.5~2倍时能显著的改善性能。(这里有个问题,图像上采样之后,网络每个层的感知域就变小了,所以大目标精度下降,中小目标提升)
采样策略 表3比较了随机采样,bootstrapping采样,混合采样。对于车辆这三种没有太大区别,对于行人,随机采样效果更差。
CNN 特征估计 我们尝试了三种学习反卷积的方法:1)双线性差值权重(bilinearly interpolated weights);2)双线性差值权重初始化,然后通过反向传播学习;3)高斯噪声初始化,然后反向传播学习。我们发现第一种方法最好。表3中显示,反卷积能在输入图像尺寸较小时提升。
嵌入语义 嵌入语义信息后,精度也有提升,但是参数会增加,因此对通道缩减能有效解决问题。
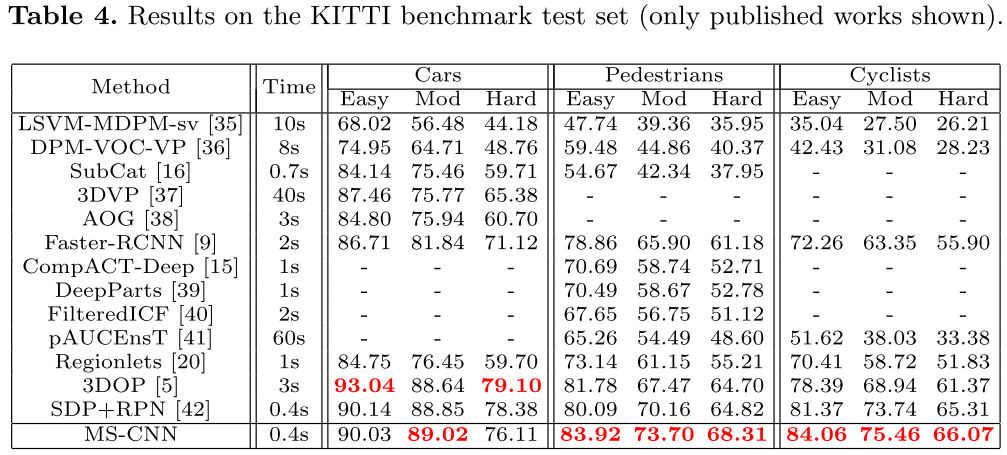
基于proposal的目标检测 相比于proposal,增加了detection后结果提升。表4是公开的KITTI上的结果。
在KITTI上比较 MS-CNN使用“h768-ctx-c”模型(所以没用反卷积?还是直接增加输入图像尺寸来的有效?)
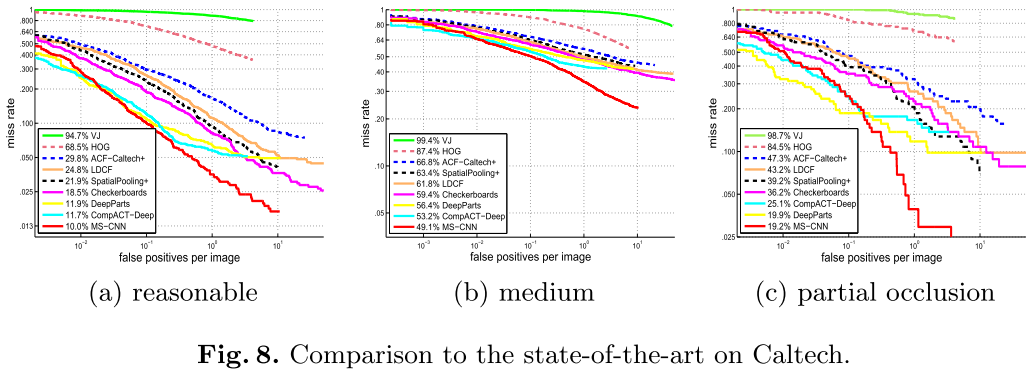
Caltech上的效果 MS-CNN使用“h720-ctx” (所以没有反卷积,没有-c)
6 结论
- 提出了一个统一的深度卷积神经网络MS-CNN,用于快速多尺度目标检测
- 在多个中间网络层进行检测,使得感知域匹配目标尺寸
- 探究了CNN特征估计(反卷积),作为输入升采样的另一种选择,能节省计算和内存开销
- 综上,MS-CNN能实现15fps的检测速度
Reference
[^1]: P. Viola and M. Jones, “Robust real-time face detection,” , IJCV, vol. 57, no. 2, pp. 137–154, 2004.
[^4]: R. Girshick, “Fast R-CNN,” In ICCV, 2015.
[^5 ]: X. Chen and Y. Zhu, “3D Object Proposals for Accurate Object Class Detection,” In NIPS, pp. 1–9, 2015.
[^6]: K. He, X. Zhang, S. Ren, and J. Sun, “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,” In ECCV, 2014.
[^7]: S. Gidaris and N. Komodakis, “Object detection via a multi-region and semantic segmentation-aware U model,” In ICCV, 2015.
[^8]: K. E. A. van de Sande, J. R. R. Uijlings, T. Gevers, and A. W. M. Smeulders, “Segmentation as selective search for object recognition,” in ICCV, 2011.
[^9 ]: S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” In NIPS, 2015.
[^11]: Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[^14]: L. Bourdev and J. Brandt, “Robust object detection via soft cascade,” In CVPR, 2005
[^15]: Cai, Z., Saberian, M.J., Vasconcelos, N.: Learning complexity-aware cascades for deep pedestrian detection, In ICCV, 2015
[^17]: Saberian, M.J., Vasconcelos, N.: Boosting algorithms for detector cascade learning. Journal of Machine Learning Research 15(1) (2014) 2569–2605
[^22]: Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In CVPR, 2015
[^26]: S. Bell, C. Lawrence Zitnick, K. Bala, and R. Girshick, “Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks,” In CVPR, 2016.
[^31]: Hosang, R. Benenson, P. Dollar, and B. Schiele, “What Makes for Effective Detection Proposals?,” TPAMI, vol. 38, no. 4, pp. 814–830, 2016.
[^32]: M. M. Cheng, Z. Zhang, W. Y. Lin, and P. Torr, “BING: Binarized normed gradients for objectness estimation at 300fps,” in CVPR, 2014, pp. 3286–3293.
[^33]: C. L. Zitnick and P. Dollár, “Edge Boxes: Locating Object Proposals from Edges,” in ECCV, 2014.
[^34]: P. Arbeláez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik, “Multiscale combinatorial grouping,” in CVPR, 2014.
Citation
1 | @inproceedings{cai2016unified, |