论文笔记《Flow-Guided Feature Aggregation for Video Object Detection》
Abstract
将图像目标检测器用于视频是具有挑战性的,其精度受外观变化的影响很大,例如,运动模糊、失焦、奇特姿势等。目前很多方法尝试引入box级别的时间信息,但是都没有实现端到端的训练。我们提出一个 flow-guided 特征集合框架实现视频目标检测端到端的学习。它在特征层面上的时间相关性。通过聚合运动路径上的临近的特征能够改善前帧特征,从而改进视频目标检测精度。本文提出的方法显著的改善ImageNet VID的单帧检测基准方法,特别是对于快速运动的目标。代码会公开。
- 中国科学技术大学
- Microsoft Research Asia
1. Introduction
近几年目标检测发展迅速,大部分都具有相似的two-stage结构。一个深度卷积神经网络用于生成特征图,一个浅层检测网络在特征图上检测目标。
这些方法在静止图像效果较好,但是直接用到视频目标检测上却存在问题。检测精度受目标外观变化的影响,例如运动模糊、视频失焦、罕见姿势等。
然而,视频中在一段时间中包含个体的信息是非常丰富。一些视频目标检测方法使用简单的策略利用这些时间信息[^18][^19][^12][^23]。首先,对单帧进行检测,然后通过专门的后处理过程在时间维度上组合BBox。这一过程依赖现成的运动估计方法,例如光流法,并且用跟踪连接BBox。一般来说,这些方法的提升主要来自启发式的后处理过程,而不是学习规则。并且没有端到端的训练,我们称这些技术为box级别的方法。
我们尝试从学习规则中开发时间信息改善检测质量。我们尝试通过集成时间改进pre-frame的特征学习。由于视频运动的原因,同一个物体的特征通常没有进行空间对准。只把特征简单聚合可能甚至恶化性能,如表1(b) 所示。因此,在学习时对运动建模是非常重要的。
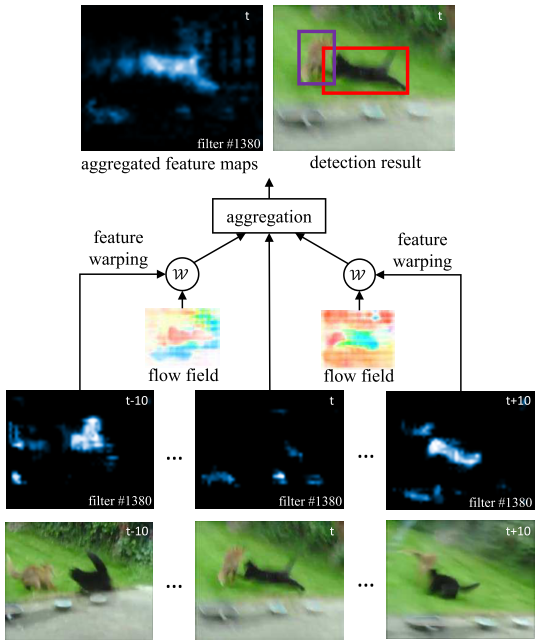
本文工作,我们提出flow-guided feature aggregation (FGFA)。如图1所示,特征提取网络对pre-frame提取特征图。为了增加reference帧的特征,使用光流光流估计nearby帧与refernce帧的运动信息。邻近帧的特征图根据flow motion 融合到 reference 帧中。
相比于其他Box级别的方法,我们的方法在特征上处理,并且进行端到端的学习,与之前的其他工作具有互补性。它改进的前帧的特征,生成高质量的BBox。Box级别的方法可以进一步优化这些BBox。我们的方法在ImageNet VID数据集上验证。严格的消融实验证实了其能够有效的改进单帧检测方法。与Box级别的方法结合可以进一步提升。
另外,我们对物体的运动强度做了分析。结果表面快速运动的物体更具挑战性,也是我们的方法提升最大的地方,其能够在一段快速运动物体上提取丰富的外观信息。
2. Related Work
图像目标检测
目前先进的目标检测方法一般基于深度神经网络。R-CNN 使用多阶段流程实现基于区域推荐的目标检测。为了加速,提出了ROI pooling来共享特征图。Faster R-CNN 提出 RPN 网络与 Fast R-CNN 共享特征。最近,R-FCN [^5] 提出在最后的 score map 进行位置敏感的 ROI pooling 操作,将特征共享推向了极限。
我们的方法更关注在视频上检测目标,其配合时间信息提升卷积特征图的质量。
视频目标检测
最近,ImageNet 提出了一个新的挑战:视频目标检测(VID)。在这项挑战中,最近的所有方法都尽在最后的BBox后处理阶段考虑时间信息。
- T-CNN[^18][^19] 通过光流预测邻近帧的BBox,然后对高置信度的BBox应用跟踪算法得到tubelets。BBox根据tubelets的分类结果进行重新打分。
- Seq-NMS[^12] 在连续帧邻近的高置信 BBox 构造序列。序列中的 Box 基于平均置信分重打分,其他接近该序列的 Box 被抑制。
- MCMOT [^23] 将后处理过程作为一个多目标跟踪问题。其使用了一系列手工规则(置信度,颜色/运动线索,改变检测点,前后验证)来验证一个BBox是否是跟踪的目标。不幸的是,这些方法是multi-stage pipeline,其一个结果依赖另一个。因此,很难修正前一个结果带来的错误。
不同的是,我们的方法在特征层级考虑时序信息,整个系统实现了端到端训练。除此之外,我们的方法也可以和这些 BBox 后处理技术配合进一步改进识别精度。
基于流的运动估计
时序信息需要在连续帧的像素或特征上建立相关性。光流广泛的用于视频分析和处理。传统方法采用变分方法主要面向小偏移。最近一些专注于大偏移[^3]并结合匹配的方法(DeepFlow[^44],EpicFlow[^31])被加入变分方法中。上述方法均采用手工特征。最近基于深度学习的方法(FlowNet [^8],及其后续方法 [^28][^17])开始采用光流。与我们的方法最相似的工作是 deep feature flow [^49],其显示出视频中信息的冗余性,并尝试提高视频的检测速度。其显示了联合训练 流-子网络和 识别-子网络的可能性。
本文,我们专注于使用连续帧的外观丰富信息来改进特征表示。我们延续 deep feature flow 的设计融合跨帧的特征。
特征集成
特征集成广泛的用于动作识别和视频描述中。一方面,目前大部分工作使用循环神经网络聚合连续帧特征。另一方面,使用 exhaustive 时空卷积来直接提取特征[^38][^21][^41][^42]。然而,这些方法中卷积核的尺寸限制了对快速运动物体建模的能力。因此,应该考虑大尺寸的卷积核,但是这样会极大的增加模型参数,并且来带过拟合的问题(这里是不是可以用膨胀卷积做)。作为对比,我们的方法基于流引导的集成,能够适应各种不同程度的运动。
视觉跟踪
最近,DCNN 也开始用于目标跟踪 [^25][^16] 并实现的不错的精度。当新跟踪一个目标,就生成一个新的网络,其共享之前的CNN层,但是具有一个新的二元分类层,并且在线更新。跟踪和视频目标检测任务显然不同,因为跟踪假设已知目标的起始位置,并且不需要预测目标类别。
3. Flow Guided Feature Aggregation
3.1 A Baseline and Motivation
对于输入的视频,我们的目的是输出所有帧中检测到的目标的BBox。一个基准方法是采用现成的目标检测其对每一帧进行独立的检测。现在基于CNN的目标检测器都具有相似的结构。一个子网络负责将图片转换为特征图 $f = N _ {feat}(I)$,然后在特征图上检测结果 $y = N _ {det}(f)$。

图2显示了目标外观剧烈变化的例子。单帧的检测结果可能由于外观的差(模糊)导致检测失败,如图1所示, $t$ 帧运动模糊。但是邻近帧具有高相应图,因此他们的特征可传递给参考帧。融合之后的特征图响应增强后实现成功检测。
为了实现特征传播和增加,需要两个模块:
- 运动引导的空间融合。估计帧间的运动然后响应的融合特征图。
- 特征聚合模块。如何合适的融合多帧特征。
3.2 模型设计
流引导融合
使用一个 flow network[^8] 来估计流场。 对于给定的参考帧 $I _ i$ 和邻近帧 $I _ j$ 则流场为 $M _ {i\rightarrow j} = F(I _ i, I _ j)$。流场和特征图的融合基于下面的公式
$$f _ {j \rightarrow i} = W(f _ j, M _ {i \rightarrow j})$$
$W(\cdot)$ 是一个双线性融合函数应用于每个通道的所有位置的特征图。
特征融合
特征经历过流引导融合后,然后再reference的特征上进行累加。我们在不同的空间位置使用不同的权重,所有通道共享权重。参考帧的融合特征为:
$$ \overline f _ i = \sum _ {j = i-K} ^{i+K} w _ {j \rightarrow i} f _ {j \rightarrow i}$$
$K$ 表示周围的邻近帧。上式与 attention 模型相似。特征融合后输入到检测网络得到结果。
$$y _ i = N _ {det}(\overline f _ i)$$
相比于其他baseline方法在box层面上融合,我们的方法大在最终结果得出前融合多帧信息。
自适应权重
自适应权重显示了所有帧每个位置相对于参考帧的重要性。如果融合特征与参考帧特征接近,则具有大的权重。我们使用余弦相似性指标来评估warped特征与参考帧特征的相似性。除此之外,我们不直接使用卷积特征,而是使用一个小的全卷积网络对特征进行变换后计算相似性。自适应权重估计为:
$$w _ {j \rightarrow i}(p) = exp(\frac{f^e _ {j \rightarrow i}(p) \cdot f^e _ {i}(p)}{|f^e _ {j \rightarrow i}(p)||f^e _ {i}(p)|})$$
其中 $f^e = \epsilon (f)$ 。权重的估计可以看成是通过SoftMax操作后的特征余弦相似性处理。
3.3 训练和推理

推理
算法1总结了推理过程。输入连续的视频帧 ${I _ i}$ 然后指定聚合范围 $K$。初始化,特征网络应用于开始 K+1 帧。然后,循环的对所有视频帧进行视频目标检测,并且计算基于光流引导的特征图。然后计算嵌入特征,接着计算聚合权重。然后计算聚合后的特征,接着输入到检测网络得到检测结果。然后计算 K+1+i 帧的特征图。继续下一帧的计算。(这里感觉有很多的重复计算,例如i和i+1,可能变化不大,但是每次都要计算光流,然后计算融合特征)。
对于运行时的复杂度与单帧检测的比例:
$$
r = 1 + \frac{(2K + 1)\cdot(O(F)+O(\epsilon)+O(W))}{O(N _ {feat}) + O(N _ {det})}
$$
一般来说,$N _ {det}$, $\epsilon$, $W$ 的复杂度是可以忽略的相比于 $N _ {feat}$。因此上式变为$r = 1 + \frac{(2K + 1)\cdot O(F)}{O(N _ {feat}) + O(N _ {det})}$ 。我们发现,其计算复杂度最大的是 $F$, 一般来说其相比 $N _ {feat}$ 是低得多的,因此是负担得起的。
训练
FGFA 整体架构是可以进行端到端训练的。并且 feature warping 模块也是采用双线性差值实现,因此也是可微的。
时间dropout。 在 SGD 中 K 的取值受到内存的限制。 我们在测试时使用大 K,但是在训练时使用小 K(=2)。在训练时,邻近帧是随机在一个大范围内采样,其等价于测试阶段。类似dropout技术,这个类似时间 dropout。从表3的效果看,这个训练策略 work well。
3.4 网络架构
下面具体描述 FGFA 模型中的每个子网络。
Flow network
我们使用 FlowNet,在 Fly Chairs dataset 上进行预训练,应用的图像具有一般的分辨率,并且输出的 stride=4 。由于 feature network 的输出 stride = 16,因此对 flow field 进行降采样以此来匹配。
Feature network
我们采用 ResNet 和 Inception-Resnet 作为 feature network。这两个网络本来用于图像识别,为了解决特征 misalignment 的问题,我们利用了修改后的版本 Aligned-Inception-ResNet[^6],在 ImageNet 分类数据集上进行预训练。
我们对预训练的模型进行了精细的调整使其应用于我们的 FGFA 模型中。我们调整了三个模块用于目标检测。我们移除了最后一个平均池化层和全连接层,并且重新训练了卷积层。为了增加特征分辨率,我们将最后一个模块的有效 stride 从32变为16,即在 conv5 的 stride 从2变为1。为了重新训练感受域的尺寸,最后一个 block 的卷积膨胀为2。最后,在顶层随机初始化 $3 \times 3$ 卷积,将特征维度减为 1024。
Embedding network
此网络包含三层,$1\times 1\times 512$,$3\times 3\times 512$,$1\times 1\times 2048$ 三个卷积层,进行随机初始化。
Detection network
我们使用 R-FCN[^5] 及其 [^49]中的设计。我们在 1024-d 的特征图上应用 RPN 子网络和 R-FCN 子网络,其分别连接开始的 512-d 特征和最后的 512-d 特征。9个 anchors(3尺度、3比例)用于RPN,每个图像产生300个 proposal。R-FCN 的位置感知得分图为 $7\times 7$ groups。
4. 实验
4.1 实验设置
ImageNet VID dataset[^33]
该数据集为流行的大尺度视频目标检测基准数据集。遵循[^18][^23]协议。模型在3862个视频上进行训练和评估,然后在555个视频上进行验证。视频帧率为25或30 fps。一共有30个目标类别,是ImageNet DET 的子集。
慢、中、快运动
为了更好的分析,我们将 GT 按其运动速度分类。物体的运动速度根据其平均 IoU (±10帧)得分进行量化,我们称其为 motion IoU,其值越低说明物体运动越快。我们按照其得分,分为 slow(>0.9),medium([0.7,0.9]),fast(<0.7)三组。举例如图4所示。
我们在评估时,分别对三种速度进行 mAP 评估。

实现细节
我们利用了 ImageNet DET 和 VID 训练集,使用了 two-phase 训练。在第一个 phase,在 ImageNet DET上训练 feature 和 Detection网络。SGD训练,一个图一个 mini-batch。120K迭代,在4个GPU上,每个GPU一个mini-batch。学习率开始的80K迭代为0.001,后40K为0.0001。在第二个phase,整个FGFA模型在 VID数据集上训练。60K次迭代,学习率开始的40K迭代为0.001,后20K次迭代为0.0001。训练和测试时,都将图像缩放为短边600像素用于feature网络,300像素用于flow网络。实验设备:E5 2670 v2 CPU 2.5GHz Nvidia K40 GPU。
4.2 消融实验
FGFA 架构设计

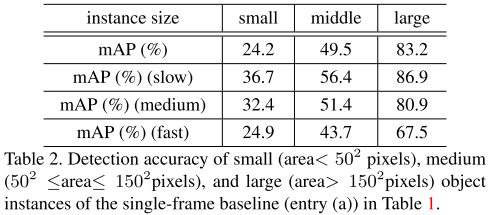
表1比较了我们的FGFA和单帧检测baseline方法。
方法(a)是单帧 baseline,其精度与原文描述的相似,说明我们的实现具有可比性且可作为评估基准。注意,我们没有增加多尺度训练、测试,语义信息,模型组合等。为了能够得到清晰可比的结果。
从结果可以看出,快速运动的物体检测非常具有挑战性。由于不同尺寸的物体可能有不同的运动速度,进一步分析了尺寸额定影响。表2实现了不同尺寸的检测精度,其结果显示,不同尺寸的物体快速运动时检测起来更加困难。
方法(b)是一个特征集合方法。没有采用光流运动。但是采用端到端训练。其性能相比于baseline略微下降。快速运动物体的下降更明显。说明在视频目标检测中考虑运动信息是非常重要的。
方法(c)增加了自适应权重模块。可以发现其对于慢、中物体的帮助较小,但是对快速运动物体的帮助更大。图5(左)看到对于快速运动物体,权重更加偏重向中间的参考帧几种。
方法(d)是本文提出的FGFA,增加了光流融合模块。同样对快速运动物体提升很大。并且图5看得出,自适应权重的分布更加平均,这说明光流引导特征集合能更有效的融合临近帧的特征。图6显示了一些结果。
方法(e)是d的降级版,不适用端到端训练。其使用baseline(a)的特征、检测子网络,已训练好的 FlowNet。在训练期间,这些网络都是固定的,只有embedding子网络进行学习。从结果看其性能降低,说明端到端学习的重要性。
FGFA使用773ms处理一帧,比单帧检测慢(288ms),因为流网络对每帧需要处理2K+1次。为了减少评估的次数,我们采用只对邻近帧进行评估的FGFA。非邻近帧的流是通过合成中间流场获得。这样,流场的计算可以在不同参考帧上复用。计算速度减少为356ms,精度下降~1%,由于流场估计错误的累加导致。
# 训练测试时的帧数
由于内存限制,我们使用ResNet-50进行实验。我们分别采用2和5帧作为mini-batch训练,1,5,9,13,17,21,25帧进行测试。结果如表3所示。2和5帧训练的结果非常接近,这也验证了temporal dropout训练策略的有效性。在测试时,我们期望精度会随着帧数的增加而提升,我们发现改进在21帧时达到饱和。因此,我们默认采用2帧训练,21帧测试。


4.3 结合Box级别的技术
我们的方法关注改进特征质量并提升视频帧的识别精度。输出bbox可以进一步通过box级别的后处理方法改进。实际上,我们测试了三种不同的技术,运动引导传播(Motion guided propagation, MGP)[^18],Tubelet rescoring [^18],Seq-NMS [^12] 。MGP和Tubelet rescoring被应用于VID比赛中,我们使用其官方的代码,然后实现了Seq-NMS。
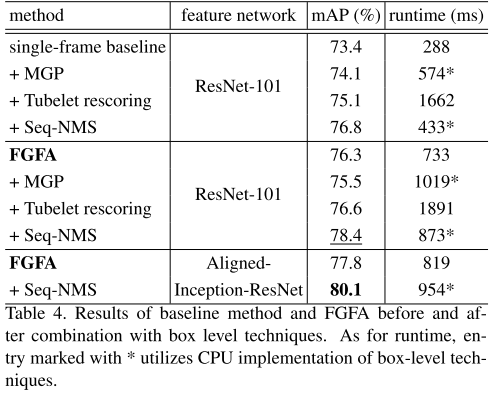
表4显示了结果。该三项技术第一次组合在单帧方法上。说明,这些后处理方法是有效的,并且可以看到Seq-NMS带来的提升最大。FGFA与那些方法配合时,只有Seq-NMS看到了提升。在使用Aligned-Inception-ResNet作为特征网络时,精度提升到80.1%,说明Seq-NMS和FGFA高度的互补。
比较其他先进系统
不像目标检测,视频目标检测缺少评估方法和比较准则。ImageNet VID 的现有方法能得到较好的结果,但是他们都是高度复杂且工程化的系统。这使得直接公平的比较不同的工作很困难。
本项工作旨在规则的视频目标检测学习框架,而不是最好的系统。FGFA相比于单帧检测方法的提升说明了其有效性。最为参考,VID 2016的冠军方法是81.2%mAP。其使用了各种技术,例如模型组合,级联检测,语义信息,多尺度推测等等。而我们的方法没有使用这些技术,就达到了80.1%的 mAP。因此我们的方法相比目前最好的工程系统具有高度的竞争性。
Reference
[^3]: T. Brox and J. Malik. Large displacement optical flow: de- scriptor matching in variational motion estimation. TPAMI, 2011.
[^5]: J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. In NIPS, 2016.
[^6]: J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y.Wei. Deformable convolutional networks. arXiv preprint arXiv:1703.06211, 2017.
[^8]: A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V. Golkov, P. v.d. Smagt, D. Cremers, and T. Brox. Flownet: Learning optical flowwith convolutional networks. In ICCV, 2015.
[^12]: W. Han, P. Khorrami, T. Le Paine, P. Ramachandran, M. Babaeizadeh, H. Shi, J. Li, S. Yan, and T. S. Huang. Seq-nms for video object detection.
[^16]: N. Hyeonseob and H. Bohyung. Learning multi-domain con- volutional neural networks for visual tracking. In CVPR, 2016.
[^17]: E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In CVPR, 2017.
[^18]: K. Kang, H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Wang, R. Wang, X. Wang, and W. Ouyang. T-cnn: Tubelets with convolutional neural networks for object de- tection from videos. arXiv preprint arxiv:1604.02532, 2016.
[^19]: K. Kang,W. Ouyang, H. Li, and X.Wang. Object detection from video tubelets with convolutional neural networks. In CVPR, 2016.
[^21]: A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convo- lutional neural networks. In CVPR, 2014.
[^23]: B. Lee, E. Erdenee, S. Jin, M. Y. Nam, Y. G. Jung, and P. K. Rhee. Multi-class multi-object tracking using changing point detection. In ECCV, 2016.
[^25]: W. Lijun, O. Wanli, W. Xiaogang, and L. Huchuan. Visual tracking with fully convolutional networks. In ICCV, 2015.
[^28]: A. Ranjan and M. J. Black. Optical flow estimation using a spatial pyramid network. arXiv preprint arXiv:1611.00850, 2016.
[^31]: J. Revaud, P. Weinzaepfel, Z. Harchaoui, and C. Schmid. Epicflow: Edge-preserving interpolation of correspondences for optical flow. In CVPR, 2015.
[^33]: O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg, and F.-F. Li. Imagenet large scale visual recognition challenge. In IJCV, 2015.
[^38]: L. Sun, K. Jia, D.-Y. Yeung, and B. E. Shi. Human action recognition using factorized spatio-temporal convolutional networks. In ICCV, 2015.
[^41]: D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional net- works. In ICCV, 2015.
[^42]: D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Deep end2end voxel2voxel prediction. In CVPR Workshop, 2016.
[^44]: P. Weinzaepfel, J. Revaud, Z. Harchaoui, and C. Schmid. Deepflow: Large displacement optical flowwith deep match- ing. In ICCV, 2013.
[^49]: X. Zhu, Y. Xiong, J. Dai, L. Yuan, and Y.Wei. Deep feature flow for video recognition. In CVPR, 2017.