Note-How Far are We from Solving Pedestrian Detection?
Abstract
在近期行人检测进展的鼓舞下,我们研究了现有方法与“完美单帧检测器”之间的差距。基于Caltech数据集创建了一个人工的基准,并且手工聚合了在顶级检测器中经常发生的错误以实现研究分析工作。研究结果刻画了定位错误、背景vs前景方面错误(虚警和漏检)。
针对定位错误,我们研究了训练集标记噪声对检测器性能的影响,结果表明仅使用小部分干净的训练数据都能使检测器的性能得到提升。针对虚警/漏检的情况,我们研究了应用在行人检测中的卷积神经网络,并且讨论了哪些因素影响了它们的性能。
除了深入的分析,我们汇报了Caltech数据集的最佳性能,并且提出了一个新的、纯净的训练/测试标注集。
1. Introduction
目标检测近年来收到了很大的关注。行人检测是其中一个典型的子问题,且由于多方面的应用,它仍然是研究的一个热点方向。
尽管在行人检测方面存在大量的研究工作,但是近期的论文仍然表现出很大的进展程度,这说明研究工作的饱和点仍未达到。在本文中,我们分析了现有技术与新创建的人工基准(section 3.1)之间的差距。结果表明,仍可以成十倍地提高技术来达到人工标注的性能。我们致力于探究哪些因素可以帮助缩小这一差距。
我们分析了拥有顶级性能行人检测器的失败案例,判断进一步推进性能需要改进的部分。分析方法有多种,包括人工检查,对有问题的案例进行自动分析,以及oracle实验(section3.2)。分析结果表明定位是高置信度虚警的重要来源。我们通过人工清理Caltech训练标注集和使用算法来处理剩余的训练样本,来提高训练集校准的质量以解决这一问题(section 3.3 and 4.1)。针对前景和背景的区别,我们研究了行人检测的卷积神经网络并且讨论了哪些因素影响了它们的性能(section 4.2)。
1.1. Related work
随着ICF(integralchannel feature,积分通道特征)检测器[6,5]的成功,许多变体[22,23,16,18]被人们提出并且显示出很大的提高。近期行人检测相关综述总结道被改进的特征一直在促进性能的提高并且很有可能继续发挥这样的作用。同时指出光流和环境信息作为图像特征的补充,将能够促进检测准确度的提高。
通过对使用外部数据进行预训练的模型进行微调,卷积神经网络也可以达到现有的最先进性能[15,20]。
近期大部分论文着眼于介绍新颖的,更好的结果,却忽视了对产生结果的系统进行的分析。有些分析工作可以建立在通用目标检测之上;与此相反,在行人检测领域,此类分析工作很少有人进行。在2008年,[21]提供了对INRIA数据集的错误分析(小部分)。在2012年的Caltech数据集调查[7]中提到的最佳方法的虚警率是本文方法的十几倍,召回率为20%,而且当时没有方法的检测率能达到95%。
由于近年来行人检测取得了较大成果,为了更好的理解未来研究的最佳切入点,基于现有检测器的一种更加深入、全面的分析是很有价值的。
1.2. Contributions
(a)提供了对现有行人检测系统的详细分析,洞察了失败案例。
(b)为Caltech行人基准提供了人工基准(human baseline),以及纯净版本的标注,用于为基准的训练和测试集提供新的、高质量的真实值。数据将会被公开。
(c)分析了训练数据的质量对检测器效果的影响大小。更具体的说,我们量化了更好地校准和更少的标注错误对于检测性能的提升。
(d)通过洞察分析,我们探索了几种获得最佳性能方法的变体:滤波通道特征检测器(filteredchannel feature detector)[23]和R-CNN检测器[13,15],并且在基线之上显现出了性能的提升。
2. Preliminaries
数据集、度量、基准检测器的描述
2.1. Caltech-USA pedestrian detectionbenchmark
最流行的数据集:Caltech-USA[7]、KITTI[11]
本次研究工作针对Caltech-USA基准数据集:
- 2.5 hours 30Hz采集自LA的街道
- 共有350,000个标注框,约2300个不同的行人
- 检测方法基于包含4024帧的测试集进行评估
- 根据标注尺寸、遮挡程度和长宽比,分为不同子集
- 规定的训练过程是每隔30帧取一帧,一共有4250帧,约1600个行人
最近有方法[16,23]采用了更精细的视频采样方法从而可以使用更多的数据进行训练,与普通的设置相比,产生的训练数据高达十倍。
2.2. Filtered channel features detector
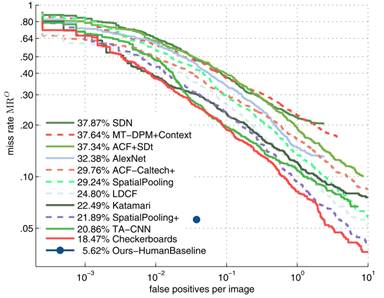
- 截止到CVPR2015,最好的方法是Checkerboards
- Checkerboards是ICF的一种,将HOG+LUV特征通道过滤后送入增强的随机森林。
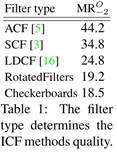
- 目前最好的卷积神经网络方法[15,20]对底层检测方法很敏感,所以首先关注优化滤波通道特征检测器的方法。(详见section 4.2)
Rotatedfilters
关于训练新模型的实验(section 4.1),我们基于LDCF实现了自己的Checkerboards。为了减少训练耗时,我们将滤波器的数量从原来实现版本中的61减少到了9。RotatedFileters是LDCF的简化版本,而且从上方表格中可以看出它相比LDCF提升了很多,并且只比Checkerboards方法的漏检率高了一个百分点,然而训练和测试时间快了六倍。
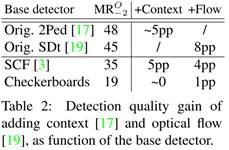
Additionalcues
综述[3]表明环境上下文信息和光流信息对检测也有所帮助。然而,随着检测器质量的提升,从这两种特征获得的结果会受到侵蚀。
3. Analysing thestate of the art
3.1.Are we reaching saturation?
问:目前的基准还有多大的发展空间?
为了回答这个问题,我们提出了一种人工的基线作为下界。我们让领域专家在Caltech-USA测试集中手工“检测”行人;如此,机器检测算法应当至少达到人工检测的性能并且最终达到超过这一性能的水平。
Humanbaseline protocol
为了确保与现有检测器之间比较的公平性,我们着眼于单帧单目检测的设置。这些视频帧以随机的(且不连续)顺序被标注,标注者只能依靠行人外观和提供的仅一帧图像中的环境上下文信息来进行标注。
- Caltech基准对检测框的长宽比进行了统一
- 手工标注:从人的头顶画一条直线至两脚中间,然后自动生成标注框,这样可以确保标注框和检测对象的中心一致
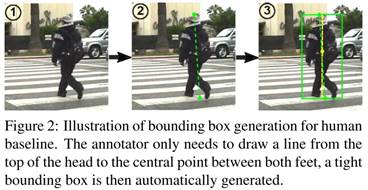
- 为了检查两组标注是否一致,对测试图像的子集(约10%)中的标注进行了复制,再分别进行评估。采用IoU≥0.5的匹配标准,结果与采用单个标注框相同。
Conclusion
我们将人工基线与其他有顶级性能的方法在测试数据的不同子集上进行了比较。我们发现人工基线在所有的情况下都远比先进检测器的性能更好,说明自动检测方法仍然有很大的提升空间。
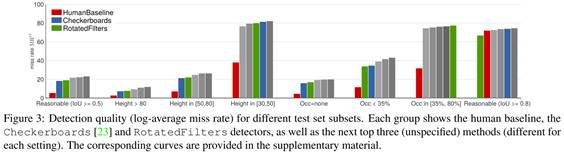
3.2.Failure analysis
问:为什么自动检测方法会失败?
本节分析Checkerboards检测发生错误的原因(代表其他高性能检测器),因为大部分顶级方法都是来自ICF族的,所以它们的情况应该相似,包括基于ICF检测器的卷积神经网络方法。
3.2.1Error sources
检测器产生的错误类型:
- false positive虚警
- false negatives漏检
在这次分析中,关注FPPI为0.1条件下的虚警和漏检情况,并且人工将它们聚类为不同的组别:
- 402个虚警
- 148个漏检
- 这些虚警和漏检情况按照错误的类型分至了不同的类别下
Falsepositives
402个虚警分为了以下11个类别,产生原因概括为定位/背景/标注错误三种:
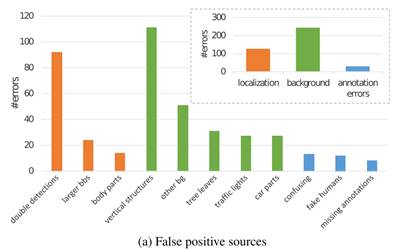
- 其中背景造成的虚警占比最大,具有垂直结构的物体造成干扰最大。这说明检测器需要扩展具有更好的垂直上下文,对大物体提供更好的可视性以及粗略的高度估计。
- 定位错误中重复检测造成虚警数占比最大,这说明改进后的检测器需要更多的定位反馈和/或另一种非极大值抑制方法。在3.3节和4.1节中探究了如何提升检测器的定位能力。
Falsenegatives
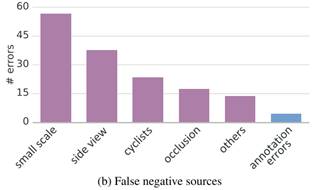
典型原因有行人尺寸过小、行人处于侧身状态。假设side-view和cyclists得分低是由于数据集的偏差,但是训练集中这两种情况的对象不多(大部分人都是在行走的),也许向训练集中补充有这些特定对象的外部图像是一个有效的策略
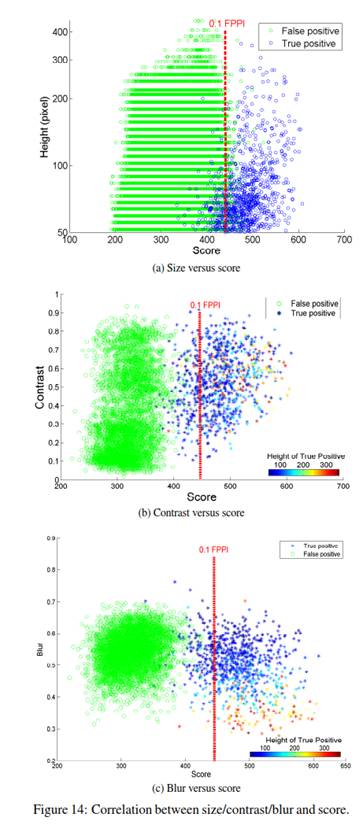
为了更好地理解关于小尺寸行人的问题,我们测量了大小、模糊度和对比度。观察到:小尺寸的行人通常都存在曝光过度或不足的情况,而且十分模糊,我们假设这是检测效果差的潜在原因(除像素数太少这个因素外)。但是我们的研究结果表明这个假设是错误的:
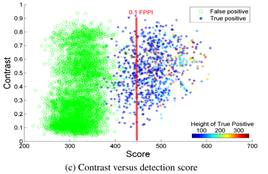
从上图看来,较低的检测得分和低对比度之间并无联系,针对模糊度的情况结果也是如此。所以检测小尺寸行人难度大的真正原因是像素的数量不足。所以要提升小尺寸对象检测率需要尽可能利用所有可以利用的像素,不仅是检测窗口内的像素,还有周围环境以及随时间变化可利用的像素。
Conclusion
已经确定来源的虚警问题可以按照上文提及的方法针对性的解决
部分漏检问题在上文中提出了解决方案,但是小尺寸和被遮挡行人的检测依然存在很大的困难需要克服。
3.2.2 Oracle test cases
An oracle experiment is used to compareyour actual system to how your system would behave if some component of italways did the right thing.
本节通过oracle实验衡量定位/背景vs前景错误对检测质量指标(log-average miss-rate)的影响
- 针对定位错误:所有与真实值重叠的虚警都被忽略,不计入评估
- 针对前景vs背景错误:所有未与真实值重叠的虚警都被忽略
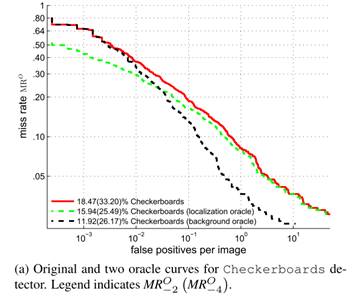
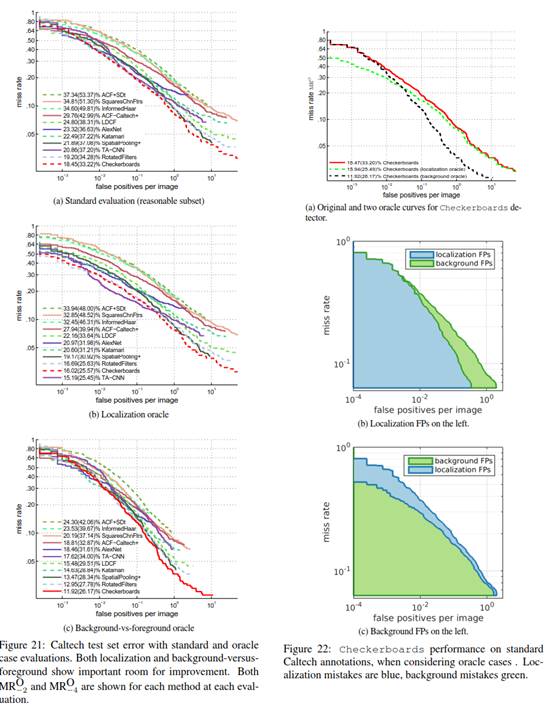
从上图可以看出修复了定位错误可以在FPPI低的区域提升性能;修复了背景错误可以在FPPI高的区域提升性能。
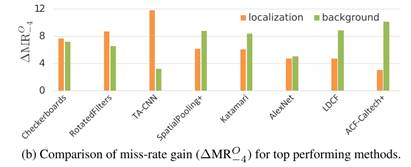
上图反映了8种顶级性能检测器在修正了定位或背景问题情况下检测效果的提升。在对比这几种检测器的过程中,我们发现大部分方法通过对这两种问题都进行修复,会在很大程度上增强检测器的性能。
Conclusion
对于大多数拥有顶级性能的方法来说,定位问题和背景/前景问题对于检测的质量同等重要。
3.3 Improved Caltech-USA annotations
改进Caltech数据集标注方法:
- 对现有检测器进行更好地评估
- 评估改进的标注方法能在多大程度上提升检测器性能
New annotation protocol
- 对训练集和测试集都进行了标注
- 在human baseline中忽略的区域和遮挡都被标注了
- 标注者允许通过整个视频来判断对象是不是人
- 允许对同一图像进行多次修改
纠正了原有标注的错误:
- 未校准
- 漏标
- 虚警
- 使用“ignore”不恰当

Betteralignment
(O代表原有标注,N代表改进的标注)
由上图可见:
- 只有使用原有标注进行训练的模型有更好的效果
- 改进的标注方法有更好的校准效果
4. 改进现有技术
在这一节中我们利用分析的结果来改进基线检测器的定位和背景与前景的辨别。
4.1. 训练标注的影响
我们想要利用新的标注来了解标注质量对检测质量的影响。首先使用不同的训练集来训练ACF[5]和RotatedFilters模型(在2.2节中介绍),并分别在原始的和新的标注上进行评估(例如$MR_{-2}^O,MR_{-4}^O,MR_{-2}^N,MR_{-4}^N$)。注意两个检测器都使用boosting进行训练,因此对标注噪声很敏感。
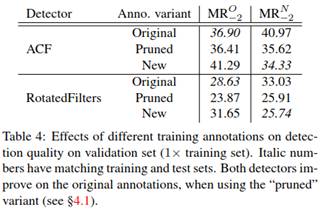
修剪收益 表4展示了使用原始的,新的和修剪的标注训练的结果(在整个训练集上进行5/6和1/6的训练和验证划分)。如预期一样,在原始的/新的标注上训练并在原始的/新的标注上测试的模型性能优于在不同的标注上训练和测试的模型。为了更好的了解新的标注的效果,我们构建了一组混合的标注。修剪的标注是允许减弱移除错误和改进校准的效果的中间点。
通过匹配新的和原始的标注来生成修剪标注(IoU $\ge$ 0.5), 并将存在在原始标注中却不在新的标注中的部分记为忽略区域,同时添加存在在新的标注中却不在原始标注中的部分。
从原始标注到修剪标注,主要做的改变是移除标注错误,而新的标注相对于修建的标注有了更好的校准。从表4中可以看出,ACF和RotatedFilters都通过移除标注错误提高了性能。这表明新的训练集比原始训练集更加纯净。
从 $M_{-2}^N$ 中可以看出更强大的检测器可以更好的从数据中受益,并可以通过移除标注错误来获得最大的检测器质量提升。

校准收益 ICF族的检测器可以通过增加的训练数据来获得提升[16, 23],使用10倍的数据要比使用1倍的数据要好(见2.1节)。为了使用新的1倍的标注来利用9倍的剩余数据,我们在新标注上训练了一个模型并使用该模型对9倍部分的原始标注进行重新校准。因为新标注有更好的校准,我们希望这个模型能改进原始标注中轻微的位置和尺寸错误。图8展示了该过程的一些结果。可以在补充材料中获取更多的细节。
表5展示了使用自动校准过程的结果和一些退化案例:使用原始的10×,使用通过原始的10×训练的模型自校准原始的10×,仅使用新标注的一部分校准原始10×(不更换1×部分)。结果表明使用检测器来改进总体数据校准十分有效,校准更好的训练数据会有更好的检测质量(在$MR^O$和 $MR^N$ 上都是如此)。这符合3.2节的分析。使用在1/2新标注上训练的模型来校准比使用原始标注获得的模型更强大。
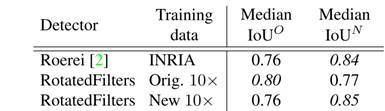
我们将使用新的标注和校准的9×数据训练的RotatedFilters模型称为Rotated-Filters-New10×。该模型在表3中也达到了high median true positives IoU,表明它在测试时确实获取了更高精度的检测。
总结 无论是改进校准还是减少标注错误来提高标注质量,使用高质量的标注进行训练都会改进整体检测质量。
4.2. 用于行人检测的卷积神经网络
3.2节的结果表明核心背景与前景的辨别任务(对象检测的分类部分)还有改进的余地。近来的工作[15,20]展示了使用卷积神经网络(convnets)来进行行人检测可以达到有竞争力的性能。我们也分析了卷积神经网络,并且探索了由检测提案质量影响的性能范围。
AlexNet 和 VGG 我们考虑了两种卷积神经网络。1)[15]中的AlexNet和2)[12]中的VGG16模型。这两个模型都在ImageNet上进行了预训练并且通过使用SquaresChnFtrs提案的Cattech10×(原始标注)进行微调。两个网络都死开源的,并且都是R-CNN架构[13]的实例。尽管他们的训练/测试时架构略有不同(R-CN与Fast R-CNN),我们希望结果差异由其各自的辨别力来支配(VGG在Pacval检测任务中[13]通过AlexNet提高了8pp mAP)。
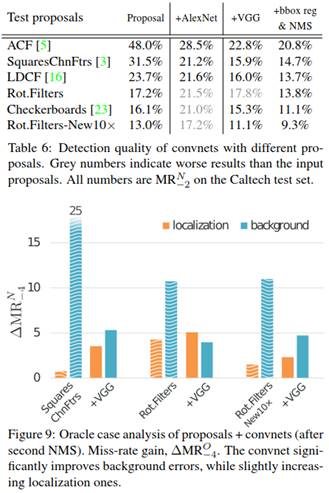
表6表示随着检测提案质量的提升,AlexNet却无法提供一致的提升,最终使ICF检测器的结果恶化([15]中有相似的观测结果)。同样,VGG在较弱的提案上有大的提升,但随着提案的改进,卷积神经网络重新获得的提升最终停止。
仔细检查所得曲线后(见补充材料),我们注意到AlexNet和VGG都为背景实例分配更低的分数,同时生成大量高分虚警。ICF检测器可以提供高recall提案,其中对象周围的虚警会分配低分值(见[15,supp,material,fig.9]),然而,卷积神经网络很难对正样本周围的这些窗口分配低分值。换句话说,尽管进行了调整,卷积神经网络的得分图仍比proposal ones模糊。由于AlexNet和VGG架构的内部特征池,我们假设这是他们的内在限制。从卷积神经网络获取峰值相应很可能需要使用不同的架构,可能更像是用于语义标注或者边界估计任务这些需要精确像素输出的架构。
幸运的是,我们可以使用边界框回归来弥补卷积神经网络评分中缺乏的空间分辨率。在VGG上添加边界回归,并应用两轮非极大值抑制(第一次在提案上,第二次在回归的框上)有收缩(contract)得分图的效果。生成多个健壮虚警前的相邻提案现在收缩成单个高分值检测。在第二个NMS上使用通用的IoU 0.5的合并标准。
0.5的合并标准。
表6最后一列表明,即使对于最好的检测器RotatedFilters-New0×,在输入提案上使用边界框回归+NMS也能获得有效的提升。在原始标注RotatedFilters-New10×+VGG上达到14.7% $MR_{-2}^O$,其改善超过[15, 20]。
图9在卷积神经网络的结果上重复了Oracle测试。可以看出VGG明显降低了背景错误,同时些微增加了定位错误。
总结 即使卷积神经网络在图像分类和通常的目标检测上与强大的结果,它们似乎在小物体周围产生良好的定位检测分值上有局限性。边框回归是在目前架构上回避这一限制的关键因素。即使使用强大的卷积神经网络,背景与前景的辨别仍是错误的主要来源;这表明神经网络的原始分类能力还有待改进。
5. 总结
这篇论文致力于分析在Caltech数据集上顶级性能的检测器的错误。人工基准(human baseline)定义了性能提升的下限。但差距还需要缩小10多倍。为了在检测过程中更好的度量下一步,我们提供了新的纯净的Caltech训练和测试集标注。
在最佳性能方法上的失败分析表明大部分错误都有很好的表征。错误特征引导了设计更好的检测器的具体建议(在3.2节提到;例如用于人侧视图的数据增加,或者在垂直轴上扩展检测器接收区域)
通过衡量更好的标注对定位准确性的影响,以及通过调查使用卷积神经网络来改善前景和背景的区分,部分解决了一些问题。结果表明正确训练的ICF检测器可以实现更好的校准,且对于行人检测,卷积神经网络在定位上能力不强,但是可以通过边界框回归来部分解决。无论在原始的和新的标注上,描述的检测方法都达到了顶级性能,具体见表7.
我们希望该工作提供的见解和数据可以指导行人检测任务中对机器和人工之间差距的缩小。
补充材料
A. 内容
补充材料提供了主要论文中提到的一些方面的更详细的见解。
- Section B提供了实验中使用到的RotatedFilters检测器的细节(2.2节)
- Section C提供了汇总不同的测试子集后的具体的曲线(图3和3.1节)
- Section D显示了分析检测器的每个错误类型的示例,讨论了尺寸,模糊和对比度评估,并更详细地回顾了oracle案例实验(3.2节)
- Section E展示了新的训练标注如何改进原始标注的示例(3.3节)
- Section F讨论了新的标注对现有方法的影响(MP排名和recall-versus-IoUcurves)(4.1节)
- Section G展示了使用1×数据自动校准10×数据的效果(4.1节)
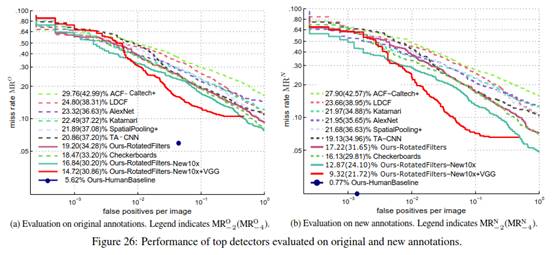
- 图26总结了原始的和新的标注的最终检测结果
B. Rotated filters检测器
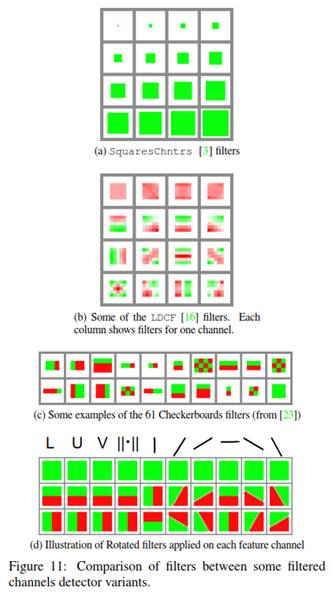
实验中使用LDCF[16]代码库重新实现了过滤通道特征Checkerboards检测器[23]。由于具有大量过滤器(每个通道61个过滤器),训练过程十分缓慢。为了加快训练和测试的过程,我们为每个通道设计9个过滤器,仍然取得了良好的性能。将新的过滤通道特征检测器称为RotatedFilters(见图11d)。
旋转过滤器由LDCF的滤波器(将PCA应用于每个特征通道获取)启发。每个特征通道的前三个过滤器是正交方向上的常量过滤器和两个阶梯函数,并具有定向梯度通道也有旋转过滤器的特性(见图11b)。旋转过滤器是LDCF的程序化版本。得到的RotatedFilters过滤器在某种程度上是直观的,而Checkerboards过滤器的功能没有其系统化和清晰。
为了整合更丰富的本地信息,与SquaresChnFtrs[3]一样,我们在每个通道上使用多种尺寸重复每个过滤器。
在Caltech验证集上,RotatedFilters使用一种尺寸(4×4)获取了31.6% $MR_{-2}^O$;使用三种尺寸(4×4,8×8和16×16)获取了28.9% $MR_{-2}^O$。因此在实验中选择了3尺寸的结构。在测试集上,RotatedFilters的性能是19.2% $MR_{-2}^O$,比Checkerboards减少了1%的损失,但在特征计算上比它快6倍。
在本文中,我们使用RotatedFilters进行所有涉及训练新模型的实验。
C. 每个测试子集的结果
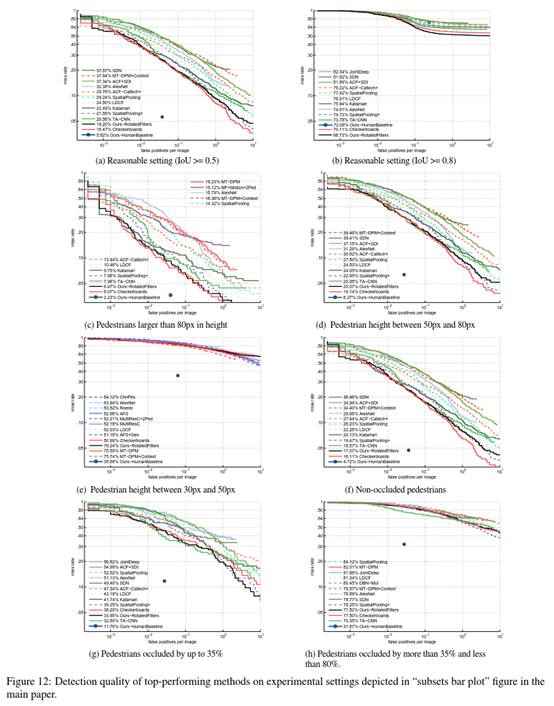
图12包含主论文(“子集条形图”)中图3的详细曲线。可以看到Checkerboards和RotatedFilters在所有子集上都有很好的性能。在其排名不在前列的案例中(例如图12e和图12h)所有的方法都表现出较低的检测质量,因此都具有相似的差评。
图12显示在Caltech数据集中Checkerboards对于很多普通案例并不是最优的,但其在各种情况下都表现出了良好的性能,因此是一个有趣的分析方法。
D. Checkerboards错误分析
错误示例 图17,18,19和20展示了主论文分析中考虑的每个错误类型的4个示例(包括虚警和负样本)。
模糊和对比度测量 为了能够分析模糊和对比度,我们定义了两种自动化措施。使用[10]中的方法测量模糊,并使用行人顶部和底部灰度值的位数差来计算对比度。
图15和16展示了使用测量的模糊和对比度的行人排名。可以看出质量测量与模糊和对比度的定性概念有很好的相关性。
尺寸,模糊或者对比度? 负样本错误的主要来源是小尺寸,但是小的行人通常具有低对比度或者模糊度。为了分析三个因素,我们观察了大小/对比度/模糊度与分数之间的相关性,如图14所示。可以看出虚警和正样本的重叠在不同层次的对比度和模糊度之间均匀分布;但是重叠在小尺寸上相当密集。因此小尺寸是影响检测质量的主要因子;而模糊度和对比度的测量并不能为检测任务提供信息。
D.1. Oracle案例
图21展示了现有方法的标准评测和oracle评测的曲线。在定位预测中,与真实值重叠的虚警不予考虑;在背景和前景辨别预测中,与真实值没有重叠的虚警不予考虑。基于这个曲线有如下发现:
- 所有方法在每个oracle评估中都有显着改善。
- 所有方法的排名在每个oracle案例下都保持相对稳定
- 定位与背景有前景的oracle测试在$MR_{-4}^O$上的改进是相当的;检测性能可以通过固定两个问题中的一个来提高。
图13中还展示了有相似分数的一些对象的示例。在低分组和高分组中,我们都可以看到行人和背景对象,这表明检测器不能充分地对前景和背景进行排序。

D.2. 对数比例视觉失真
本文展示的oracle实验的结果模拟了一种我们不会产生的错误:删除了触摸标注的行人错误(定位预测)或者位于背景上的错误(背景预测)。
要注意这是仅有的两种虚警。如果我们移除了这两种类型的错误,结果将是一个有非常低错误率的水平线。
由于Caltech性能曲线上的双对数比例看起来像是两个oracles都可以稍微改进性能,但是情况并非如此,大部分的错误都是由不同类型的错误引起的。
图22说明了双对数尺寸歪曲面积的多少。我们经常将平均错误率视为曲线下的面积,因此可以通过其类型对图中的虚警进行颜色编码:该图显示了每个点上定位(蓝色)和背景(绿色)错误之间的比率,这也是整个曲线的比率。22b和22c的两个曲线都展示了同样的数据,唯一的区别在于左侧展示了定位,右侧展示了背景。由于双对数尺寸,绘制在左边的错误类型似乎主导了度量
E. 改进的标注
图23在测试集中的示例帧上展示了原始(红色)和新的(绿色)标注。从比较中可以看出,新的注释与行人更加一致。这是由于头和脚更靠近新的边界框的中心。
F. 原始标注和新的标注的评估
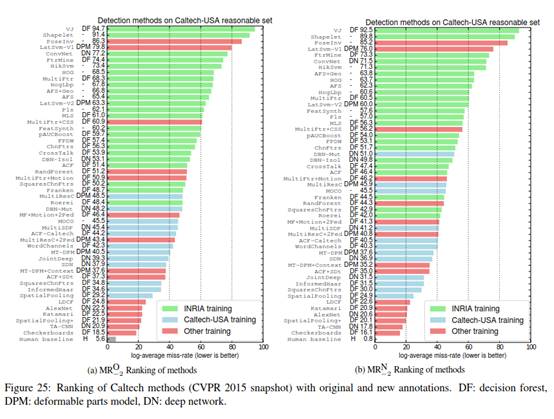
排名 图25显示了在 $MR_{-2}^O$ (原始标注)或 $MR_{-2}^N$(提出的新标注)上进行评估时,所有已有的Caltech方法在CVPR 2015之前的排名。虽然排名有一些变化(例如JointDeep与SDN),总体趋势仍然保持不变。改进的标注与之前的标注不是完全相反的,这是一个好的迹象。如论文(以及补充材料的其他部分)所讨论的,改进的标注对于未来的方法(MR进一步下降)以及曲线的低FPPI区域(高信度错误)至关重要。
RotatedFilters 图26a和26b展示了RotatedFilters,Rotated-Filters-New10x和RotatedFilters-New10x-+VGG方法分别在原始的和新的标注上的结果。在训练期间使用改进的标注(-New10x)确实提高了原始和新标注的结果。
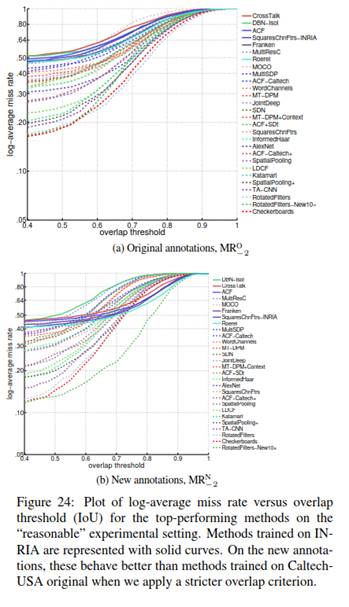
MR与 IoU主论文的3.3节(和表3)讨论了新标注如何更好地校准的经验性措施。我们在这楼里提供更多的细节。图24绘制了顶级性能方法的 $MR_{-2}^O$ 和$MR_{-2}^N$ 和将检测作为正样本的重叠标准(IoU阈值)。标准评测使用0.5的IoU阈值。图中在INRIA上训练的方法是连续的线,在Caltech上训练的方法是虚线。
在图24(原始标注)中,由于重叠阈值十分严格,方法的排序保持稳定。(与[7]中观察结果一致)。有趣的是,图24b(新标注)可以观察到不同的趋势。在评测 $MR_{-2}^N$(新的标注)时,我们发现在INRIA上训练的方法,虽然在IoU=0.5时表现不佳,但在较高的IoU下表现相对较好,最终超过了原始Caltech数据训练的所有方法。我们认为INRIA训练数据质量更好(校准更好的训练样本),因此检测器能更好的学习定位。原始和新标注之间的这种差异使得改进的标注在定位方面表现更好。主文章中的表3提供了图24的总结版本。
G. 校准Caltech10×的影响
从图24b中可以看出,使用半自动校准的Caltech10×训练数据显著提升了定位质量。从RotatedFilters到RotatedFilters-New10×,$MR_{-2}^N$在整个IoU范围内均有改进。图27显示了在10×训练数据上进行校准过程的定性结果。