Note Seq-NMS for Video Object Detection
Abstract
用于视频目标检测的NMS方法
1. Introduction
视频目标检测困难的原因:
- 较大的尺度变化
- 遮挡
- 运动模糊
本文,我们提出单帧检测的一个简单拓展来帮助解决上述问题。
单帧检测完全忽略了时间维度,本文,我们在后处理阶段融合时序信息,以此优化每帧的检测结果。对于给定的时间序列上的ROI和类别得分,我们使用简单的重叠标准来连接邻近帧的BBox,使得序列的得分最大化。之后抑制附近的BBox,然后对BBox重打分。

贡献:
- 提出Seq-NMS改进用于视频视频数据的物体检测流程。特别地,我们改进了后处理阶段,使用前后帧的高分物体结果增强弱检测结果。
- Seq-NMS在ImageNet VID上的表现超过先进的单帧检测结果。
- 方法在ILSVRC2015上排名第3
2. 我们的方法
2.1 Seq-NMS
NMS经常会选错BBox,选择的BBox通常较大,且与GT与较小的IOU。大BBox经常有较高的物体得分,可能是在ROI pooling时大BBox能提取更多的信息。为了解决这个问题,我们尝试使用时序信息对bbox重排序。我们假设邻近帧有相同的物体具有相似的位置和尺寸。
我们提出一些经验性的方法:1)序列选择,2)序列重打分,3)抑制。重复此步骤直到没有剩余序列为止。图1显示了此过程。

序列选择
当IoU超过一定阈值后,第一帧的一个BBox与第二帧的BBox连接,我们首先选择潜在的可能的所有连接。然后尝试找到得分最大的序列。
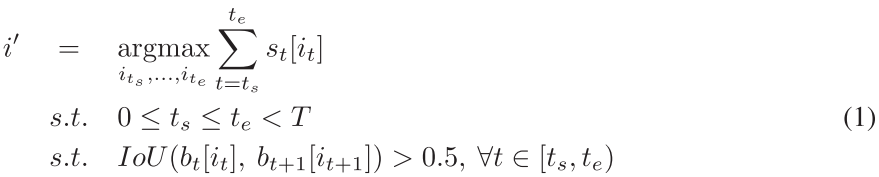
可以通过简单的动态规划算法求解。
序列重打分
尝试使用average或max函数对序列打分
抑制
选择后的BBox重候选BBox中移除,并且对IoU超过阈值的BBox抑制。
3. 数据集
ImageNet VID数据集,30个类别
4. 结果
4.1 RPN和分类器训练细节
首先,在VID训练集上迭代400K次,Fast R-CNN训练迭代200K次。最后固定卷积层,训练400K次,发现RPN在VID验证集上实现90%的召回率。
对于分类器,我们考虑ZF和VGG16两个网络,ZF在VID的训练集上训练,VGG16在2015DET的训练和验证集上预训练。然后VGG在VID上训练,去掉多余的类别单元,然后固定其他层。
4.2 定量结果
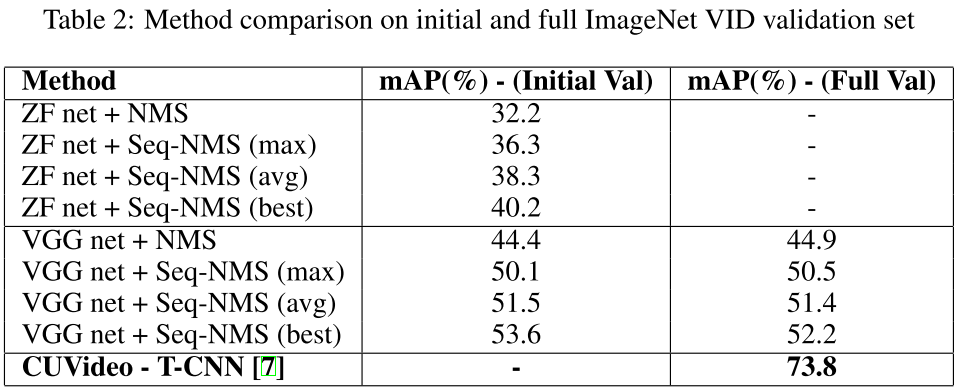
NMS表示单帧检测,best是表示每个类别选择其最优的策略,然后求其平均。表2显示检测结果。
图3显示了每个类别的mAP的提升,图4显示了每个类别的提升。可以发现,摩托车、海龟、小熊猫、斑马、羊的提升较大。
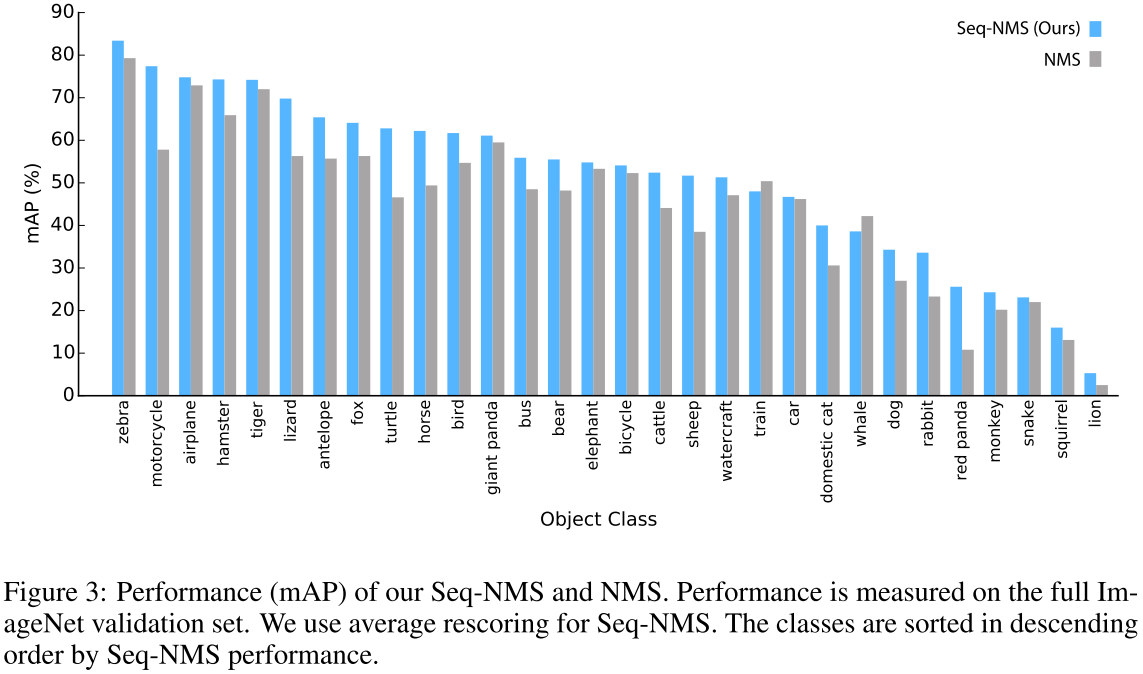
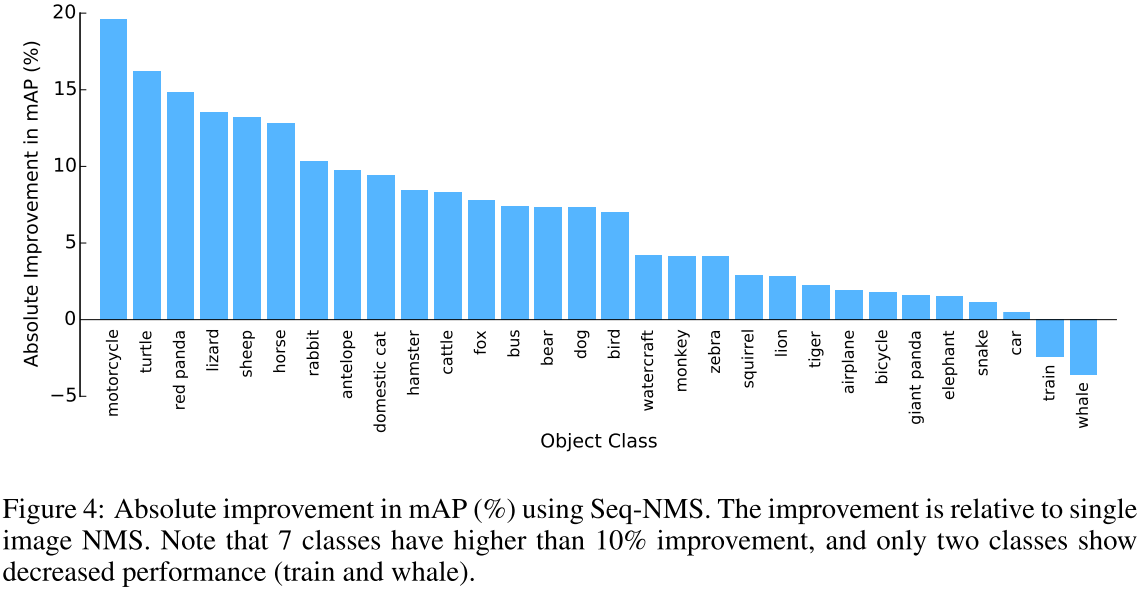
表3显示了VID比赛的结果,我们提交的最好结果是48.7%。
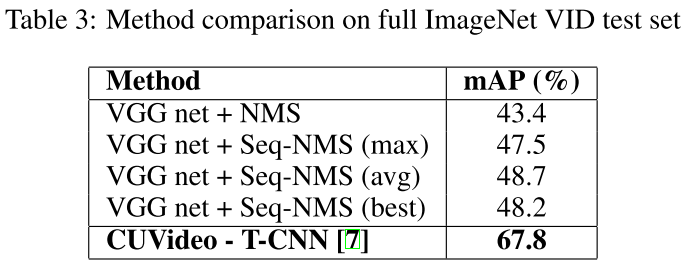
T-CNN的方法包含以下技术:1)很强的单帧检测器;2)bbox抑制和传播;3)轨迹/tubelet 重打分;4)模型组合。其单帧检测器的mAP可达到67.7%如果仅考虑后面两个技术的提升,我们的方法提升更大(7.3% vs. 6.7%)。
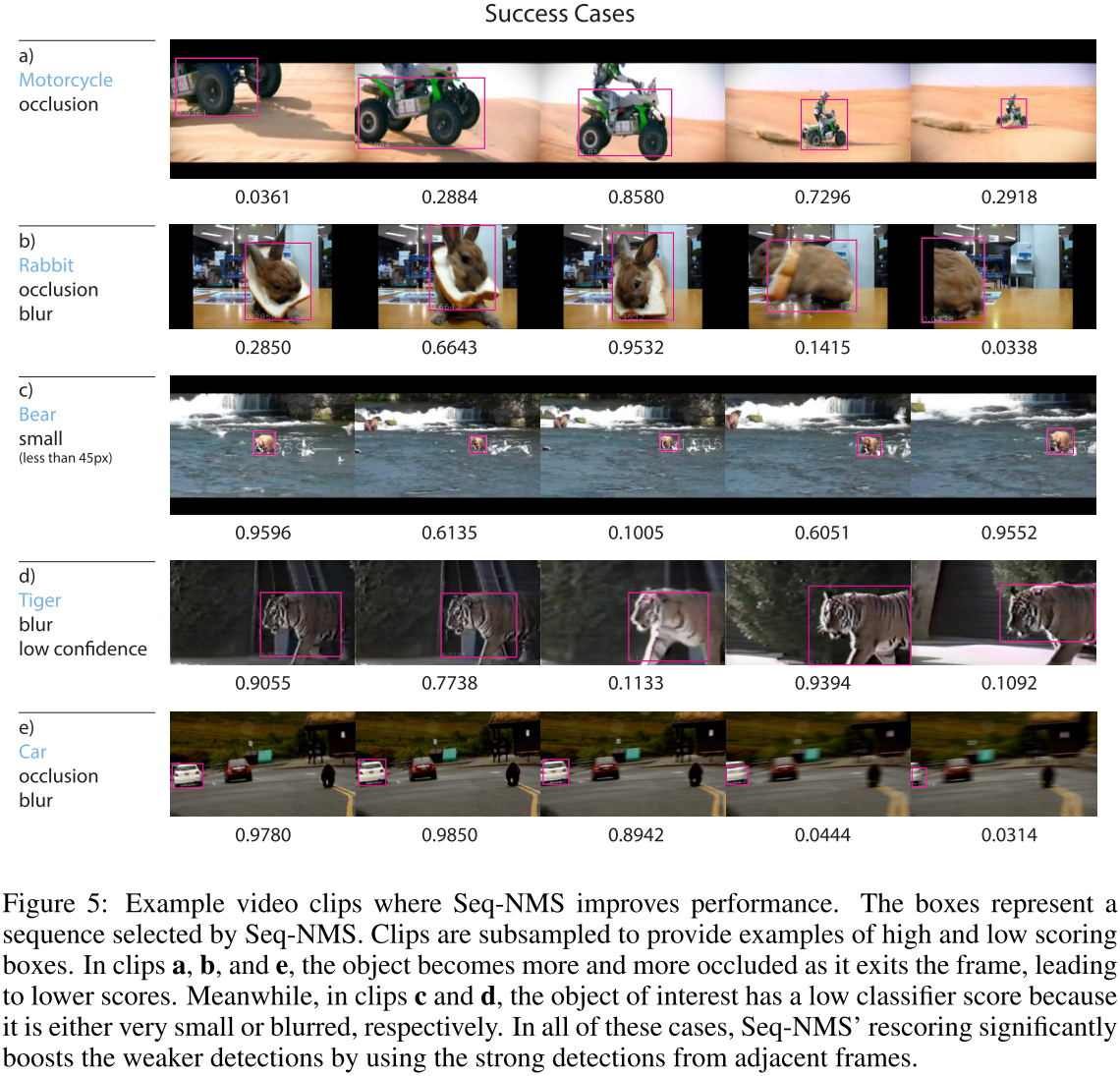
4.3 定性分析
Seq-NMS可以把一些低得分的物体重新找回,但是也可能带入一些虚警。